1 引言
近年来,在全球实现“双碳”目标的背景下,新能源汽车的发展有助于减少温室气体的排放、改善生态坏境,因而得到了全球各国的重视。而随着新一轮科技革命和产业变革的兴起,我国的新能源汽车产业也进入了加速发展的阶段[1 ] 。电动汽车电池的容量会随着充放电循环次数的增加而衰减,因此,对于电池容量的准确预测有助于为电池在使用寿命结束之前的更换提供指导,对提升用户的使用体验格外重要[2 ] 。
目前,电池容量估计的方法主要包括直接测量法、基于模型的方法和基于数据驱动的方法三类。直接测量法是在实验室条件下对电池的开路电压、充放电电流、内阻等指标进行离线测量,然后再通过相应的公式等计算电池的容量。这种方法计算简单且容易实现,但是需要将目标电池从电动汽车上取下来,难以用于计算工作状态下的动力电池的容量[3 ] 。基于模型的方法依赖于寿命衰减模型、经验模型和等效电路模型,通过搭建空间状态模型表征电池内部电化学机理,然后利用非线性状态估计器或者自适应滤波等更新参数来进行电池容量的估计[4 ] 。但是,现有的基于电化学模型方法在试验过程中需要特定的设备来获取锂离子电池的内部机构,检测时间过长,效率较低,无法满足容量预测的要求[5 ] 。
基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] 。文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化。文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度。
然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降。此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象。因此利用实际的数据进行容量预测的难度较大。此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义。
本文以实车行驶数据作为主要的研究对象,针对实车数据采集过程中SOC数据精度较低等问题,采用SOC插值和滑动窗口移动平均法,利用安时积分法计算容量,采用卡尔曼滤波算法拟合了容量和里程的曲线,并以输出值作为最终容量的真实值,针对电动汽车容量退化趋势中存在的短期波动的问题,首先通过集合经验模态分解(Ensemble empirical mode decomposition, EEMD)将容量分解为长期退化趋势和短期波动,并采用局部支持向量机(Support vector machine, SVM)和多输出混合高斯过程(Multi-output mixture of Gaussian process, MOMoGP)分别对EEMD分解后得到的长期趋势和短期波动进行建模预测,有效提高了容量预测精度。
2 实车电池容量提取
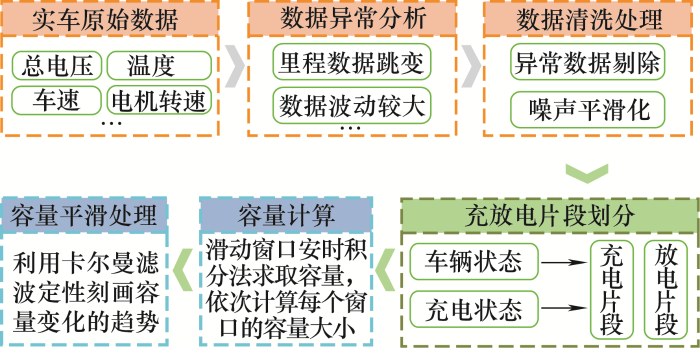
本文选择新能源汽车国家大数据联盟提供的3辆新能源汽车近1年的实时运行数据进行车用电池容量分析和预测,其中数据集包含电池电压、电池电流、累计里程、充电状态等40个参数,采样间隔为10 s。由于实车数据在传输过程中存在信号延迟、错报甚至丢失的情况,造成累积里程跳变、数据波动较大等数据异常,因此首先采用基于3-$\sigma $ [13 ] 等数据预处理方法,以剔除掉原始数据集中异常和离群数据。图1 展示了原始数据预处理的总体流程。
图1
与在实验室标准环境中得到的满充满放数据相比,电动汽车车主一般不会在电池电量过低时充电,这导致每个充电片段的起始和终止SOC都是不同的,因此首先需要选取一段固定的SOC范围进行分析,本文选取SOC位于50%~80%段的数据,因为首先大部分的充电片段都包括这个区间的数据,可用的充电片段较多,有利于预测模型的构建;其次,50%~80%段的数据包括了足够多的信息,有利于容量的提取;最后,这个区间段内电池电压电流变化相对来说比较稳定,且具有代表性。此外,电动汽车电池的放电数据采集于汽车运行阶段,干扰因素较多,而充电数据的采集都是在停车时进行的,具有比较稳定、不受干扰的特点。
因此,对清洗后的数据集进行片段划分,提取出充电段实车数据作为容量计算依据。
由于原始数据中没有直接给出容量数据,因此利用选取充电片段中的SOC数据、电流数据等进行求解。对每一个充电片段,使用安时积分法计算对应的电池容量值。其数学形式如式(1)所示
(1) $C=\frac{\sum\limits_{k}^{s}{\eta }I\Delta t}{\Delta \mathrm{SOC}}$
式中,k 为充电开始时对应的数据点;s 为充电结束时对应的数据点;ΔSOC=SOCk s k s $\eta $ $\eta =1$ I 为充电电流;t 为充电过程中的时间变量。
对于每一个充电片段,为了减小由于采样时间跨度过大造成的误差,采用滑动窗口移动平均的方法来计算每个充电过程中的电动汽车电池容量大小[14 ] 。从起点开始,以20个数据点为一个窗口,应用安时积分法计算该窗口的电池容量大小,然后依次滑动窗口至充电终点,最后计算所有窗口容量均值作为该充电过程电池容量。如式(2)所示
(2) $C=\frac{\sum\limits_{i=1}^{n}{{{C}_{i}}}}{n}$
式中,C 为充电片段的容量;${{C}_{i}}(i=1,2,\cdots,n)$ i 个滑动窗口的容量;n 为滑动窗口的个数。
上述计算得到的容量值中,存在远离数据中心的离群点,这些离群点会影响后续模型的精度,因此需要剔除这部分异常数据。由于容量数据集中异常值具体信息未知且数据量较大,因此采用基于密度的聚类算法(Density-based spatial clustering of applications with noise, DBSCAN)来进行离群值的剔除[15 ] 。
卡尔曼滤波是一种高效的自回归滤波器,它能在存在诸多不确定情况的组合信息中估计动态系统的状态,适用于在含有不确定因素的动态线性系统里找到系统当前状态的最优解[16 ] 。为了减少过程噪声和测量噪声对容量计算结果的影响,进一步提高容量计算精度,设计如下卡尔曼滤波器
(3) ${{C}_{k}}={{\hat{C}}_{k}}+{{K}_{k}}({{z}_{k}}-H{{\hat{C}}_{k}})$
(4) ${{K}_{k}}=\frac{{{P}_{-k}}{{H}^{\mathrm{T}}}}{H{{P}_{-k}}{{H}^{\mathrm{T}}}+Q}$
(5) ${{P}_{k}}=(I-{{K}_{k}}H){{P}_{-k}}$
式中,Ck 为k 时刻容量的后验修正值;Kk 为k 时刻的卡尔曼增益;zk 为k 时刻的观察值;H ${{\hat{C}}_{k}}$ k 时刻的容量先验估计;${{P}_{-k}}$ k 时刻的先验协方差矩阵;Q 为过程噪声协方差;P k k 时刻的后验协方差矩阵。
3 模型构建
3.1 问题描述
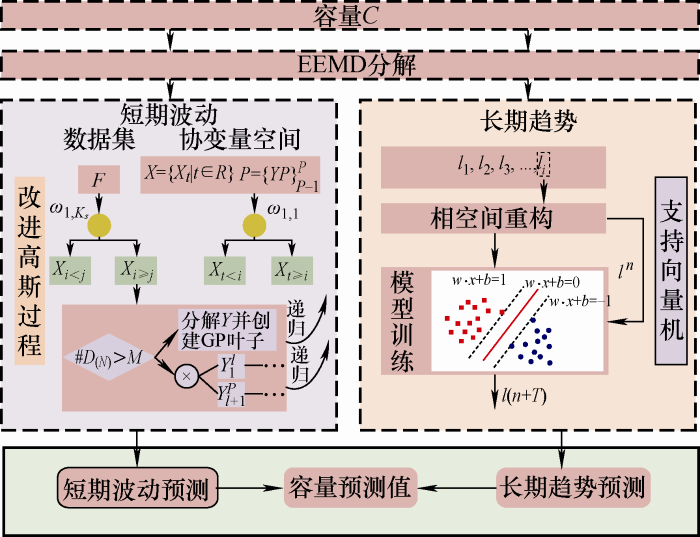
随着电动汽车行驶里程的增加,电池容量会呈现衰减的趋势,但是由于在实际运行过程中行驶工况复杂、驾驶员驾驶行为不同等因素,导致容量的下降过程存在波动,而并不是一个光滑的曲线。因此,为了准确估计电池的未来容量,关键是考虑衰减趋势上的波动性,因此本文将容量C 通过EEMD分解为
(6) $C=L+F$
式中,L 为容量C 的长期退化趋势;F 为短期波动。这两部分的数值特征是不同的,即长期趋势部分实际上是具有线性趋势的非平稳序列,而短期波动部分是具有周期波动特征的非平稳序列。本文通过结合局部支持向量机和MOMoGP来分别针对L 和F 进行建模,然后将L 和F 相加得到最终的容量预测结果,以提高模型的预测能力。图2 展示了所提方法的总体框架。
图2
3.2 EEMD分解
EEMD具有处理非平稳数据序列的能力,在EMD分解中,得到的IMF可能存在着模态混叠的现象,影响分解效果,在文献[17 ]中提出了一种新的EEMD方法来解决这个问题,高斯白噪声具有频率均匀分布的统计特性,而EEMD利用该特性通过每次加入同等幅值的不同白噪声来改变信号的极值点特性,之后对多次EMD得到的相应IMF进行总体平均来抵消加入的白噪声,从而有效抑制模态混叠的产生。EEMD分解之后,L 和F 作为两个部分在下一步中用于单独的模型训练。
3.3 局部支持向量机
支持向量机模型以结构风险最小化为基础,利用回归方法来解决非线性问题[18 ] ,而电动汽车电池的容量受到很多因素的影响,如电流、放电深度和环境温度等,且这些影响因素与容量衰减之间并不是简单的线性关系,因此对于长期容量下降趋势,采用局部支持向量机模型来对其进行建模。
SVM的主要任务是找到一个函数 $f(x)=w\cdot \phi ({{x}_{i}})+b$ $R[f]=\int{c}(x,y,f)\mathrm{d}P(x,y)$ c 是损失函数,观测值y 和预测值f (x )之间的误差可以通过式(7)描述的ε 不敏感损失函数来计算
(7) $E(w)=\frac{w\cdot w}{2}+\frac{C\sum\limits_{i=1}^{l}{{{\left| {{y}_{i}}-f({{x}_{i}},x) \right|}_{\varepsilon }}}}{l}$
式中,${{\left| \begin{matrix} {{y}_{i}}-f({{x}_{i}},x) \\\end{matrix} \right|}_{\varepsilon }}=\max \left\{ \begin{matrix} 0,\left| \begin{matrix} {{y}_{i}}-f({{x}_{i}},x) \\\end{matrix} \right|-\varepsilon \\\end{matrix} \right\}$ ε 不敏感损失函数,${(w\cdot w)}/{2}\;$ f (x )的复杂性,$C\sum\limits_{i=1}^{l}{{{{\left| {{y}_{i}}-f({{x}_{i}},x) \right|}_{\varepsilon }}}/{l}\;}$ C 表示复杂性和损失之间的关系,相当于
(8) $\left\{ \begin{align} & \underset{\alpha,{{a}^{*}}}{\mathop{\max }}\,\sum\limits_{i=1}^{I}{\left[ \alpha _{i}^{*}({{y}_{i}}-\varepsilon )-{{\alpha }_{i}}({{y}_{i}}+\varepsilon ) \right]-} \\ & \text{ }\frac{1}{2}\sum\limits_{i=1}^{I}{\sum\limits_{j=1}^{I}{({{\alpha }_{i}}-\alpha _{i}^{*})K({{x}_{i}},{{x}_{j}})}} \\ & \mathrm{s}.\mathrm{t}.\text{ }\sum\limits_{i=1}^{I}{({{\alpha }_{i}}-\alpha _{i}^{*})=0\text{ }\ \ \ \ 0\le {{\alpha }_{i}},\alpha _{i}^{*}\le C/l,i=1,\cdots,l} \\ \end{align} \right.$
式中,$K({{x}_{i}},{{x}_{j}})=\phi ({{x}_{i}})\phi ({{x}_{j}})$ ${{\alpha }_{i}}$ $\alpha _{i}^{*}$ $\overline{\mathbf{a}}={{[\overline{{{\alpha }_{1}}},{{\overline{{{\alpha }_{1}}}}^{*}},\overline{{{\alpha }_{2}}},{{\overline{{{\alpha }_{2}}}}^{*}},\cdots,\overline{{{\alpha }_{l}}},{{\overline{{{\alpha }_{l}}}}^{*}}]}^{\mathrm{T}}}$ x
(9) $f(x)=w\cdot \phi (x)+\bar{b}=\sum\limits_{i=1}^{l}{(\overline{{{\alpha }_{i}}}-{{\overline{{{\alpha }_{i}}}}^{*}})K({{x}_{i}},x)}+\bar{b}$
而局部ε -SVM通过相空间重构得到不同的向量,然后选择与输入向量最接近的向量用于训练模型,其建模过程如下所示。
步骤1:对于输入序列l (t ),选择嵌入维度m 和延迟时间τ ,根据Takens嵌入定理重构相空间。对于用来预测下一个点的输入向量L N ),计算目标向量与预先形成的N -1个向量之间的距离为
(10) $d(i)=\left\| L(i)-L(N) \right\|\ \ \ \ \ \ i=1,2,\cdots,N-1$
步骤2:选择与向量L N )最接近的p 个向量,并求出对应的Dr 值
(11) $\begin{matrix} L_{r}^{n}={{\left[ l({{t}_{r}}),l({{t}_{r}}+\tau ),l({{t}_{r}}+(m-1)\tau ) \right]}^{\mathrm{T}}} \\ r=1,2,\cdots,p \\ \end{matrix}$
(12) ${{D}_{r}}=x({{t}_{r}}+m\mathrm{ }\!\!\pi\!\!\text{ })\ \ \ \ r=1,2,\cdots,p$
步骤3:将$L_{r}^{n},r=1,2,\cdots,p$ ${{D}_{r}},r=1,2,\cdots,p$
步骤4:将L N )作为支持向量机的输入向量,得到预测值l (n +T )。
3.4 MOMoGP
高斯回归过程是一种贝叶斯回归方法,其优点是只需要小数据集,并且是一种非参数回归模型。高斯回归过程已经广泛地用于电池的剩余寿命预测[19 ] ,MOMoGP[20 ] 是一种改进的多输出高斯过程算法,它可以准确捕捉输出维度之间的相关性,更好地利用高维空间预测容量的短期波动。
当给定一个观测值$\mathfrak{D}=\left\{ ({{x}_{n}},{{y}_{n}}) \right\}_{n=1}^{N}$ xn ∈R D yn ∈R P F ,对观测值yp 进行建模
(13) ${{f}_{p}}\mathrm{GP}(0,K)$
(14) ${{y}_{p}}|{{f}_{p}}N\left( {{f}_{p}}(x),I,{{\sigma }^{2}} \right)$
式中,K S ,后验推理为
(15) $\begin{matrix} {{p}_{\text{s}}}(f\mid \mathfrak{D})\propto \prod\limits_{(x,y)\in \mathfrak{D}}{p}\left( y\mid {{f}_{n}} \right)\sum\limits_{N\in \text{ch}(S)}{{{w}_{\text{S},\text{N}}}}{{p}_{\text{N}}}\left( {{f}_{n}}\mid {{x}_{n}} \right)\ = \\ \text{ }\sum\limits_{N\in \text{ch}(S)}{{{w}_{\text{S},\text{N}}}}\underbrace{\prod\limits_{\left( {{x}_{n}},{{y}_{n}} \right)\in \mathbb{D}}{p}\left( {{y}_{n}}\mid {{f}_{n}} \right){{p}_{\text{N}}}\left( {{f}_{n}}\mid {{x}_{n}} \right)}_{={{p}_{\text{N}}}(f\mid \mathfrak{D})} \\ \end{matrix}$
当用于预测时,在给定下一个预测周期x 的情况下,多模态后验预测分布可以通过从叶到根自下而上传播的一阶矩和二阶矩来近似。分割输出空间的乘积节点P 执行来自其k 个子节点的平均值(预测值)的串联和节点S 对应于多元高斯分布的混合。
(16) ${{m}_{p}}({{x}^{*}})=[{{m}_{{{N}_{1}}}}({{x}^{*}}),\cdots,{{m}_{{{N}_{k}}}}({{x}^{*}})]$
(17) ${{V}_{p}}({{x}^{*}})=\text{diag}[{{V}_{{{N}_{1}}}}({{x}^{*}}),\cdots,{{V}_{{{N}_{k}}}}({{x}^{*}})]$
(18) ${{m}_{S}}({{x}^{*}})=\sum\limits_{N\in \mathrm{ch}(S)}{{{\omega }_{\mathrm{S},\mathrm{N}}}}{{m}_{\mathrm{N}}}({{x}^{*}})$
预测值可以视为MOMoGP的后验分布平均值,因此,预测的未来短期波动现象 $\hat{f}(k+1)$
(19) $\hat{f}(k+1)=m\left( {{x}^{*}} \right)$
4 结果及分析
4.1 数据预处理结果
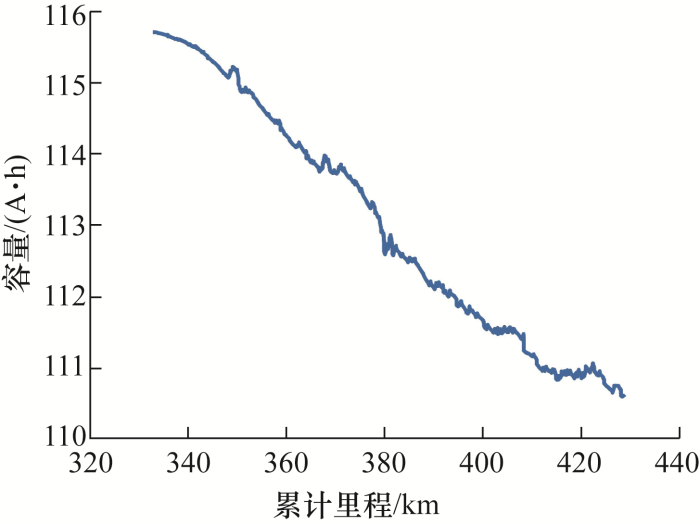
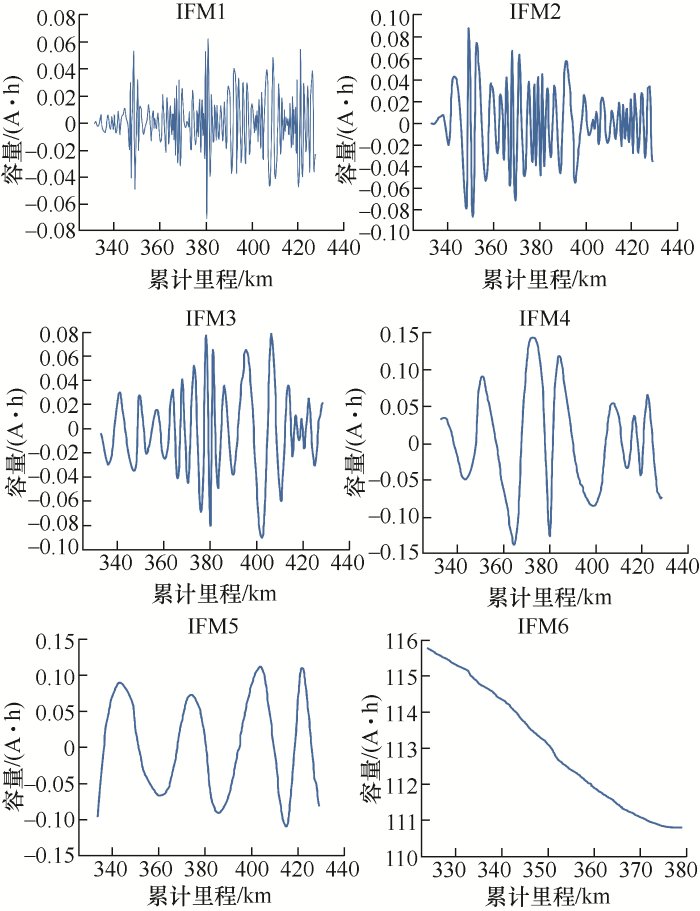
图3 和图4 分别展示了实车1原始容量和经过EEMD分解后的5个IMF以及残差,其中IMF1、IMF2、IMF3表现出了强烈的波动,因此将其看成短期波动部分,IMF4、IMF5以及残差较为平稳,因此将其看成容量退化的长期趋势。
图3
![]()
图4
4.2 电池容量预测结果
为了分辨预测结果的好坏,本文采用均方根误差(Root mean square error, RMSE)、平均绝对误差(Mean absolute error, MAE)和平均绝对百分比误差(Mean absolute percentage error, MAPE)来判定模型与容量衰减曲线的拟合情况,其计算公式为
(20) $\mathrm{RMSE}=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}{{{\left( {{{\hat{y}}}_{i}}-{{y}_{i}} \right)}^{2}}}}$
(21) $\mathrm{MAE}=\frac{1}{n}\sum\limits_{i=1}^{n}{|}{{\hat{y}}_{i}}-{{y}_{i}}|$
(22) $\mathrm{MAPE}=\frac{100%}{n}\sum\limits_{i=1}^{n}{\left| \frac{{{{\hat{y}}}_{i}}-{{y}_{i}}}{{{y}_{i}}} \right|}$
式中,n 为预测次数;yi 为第i 次预测的真实值, ${{\hat{y}}_{i}}$ i 次的预测值。计算结果越接近0,说明预测结果越精确。
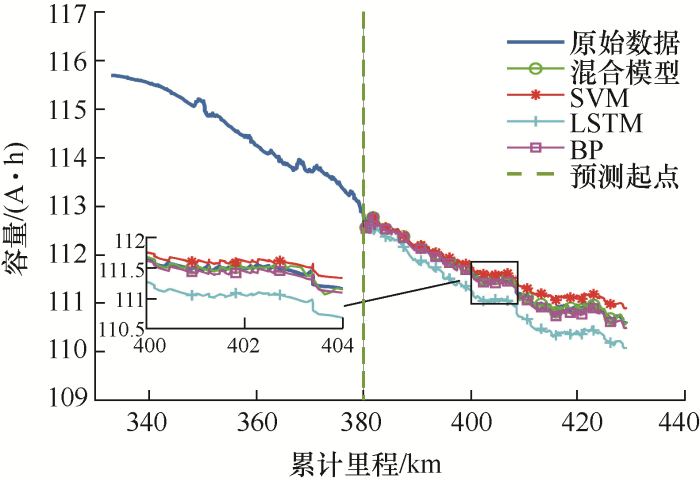
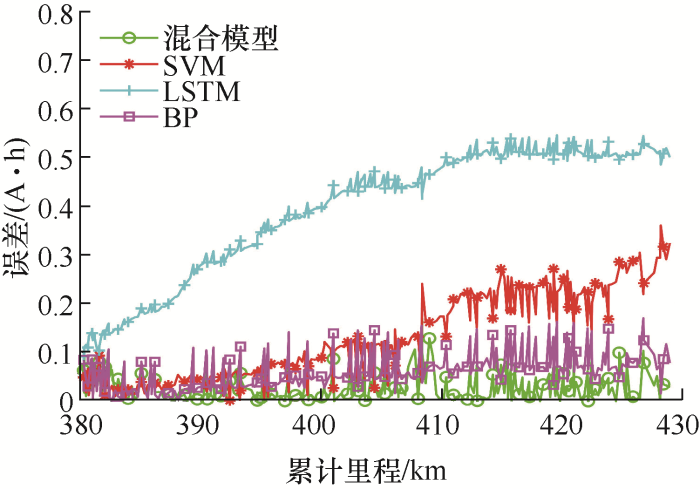
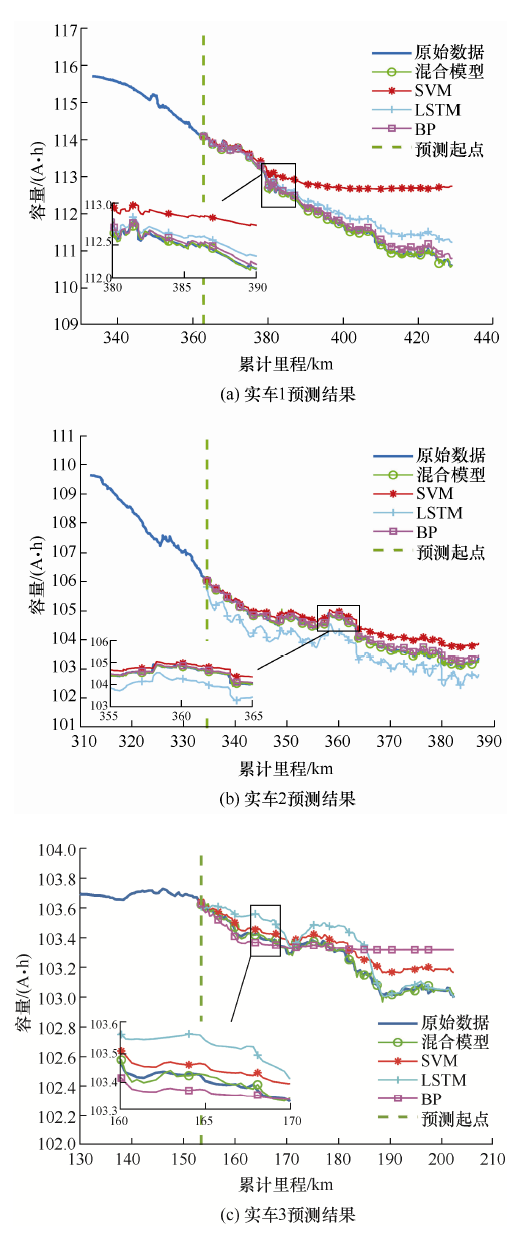
为了验证算法的有效性,建立了融合模型,利用了三辆车,实车1、实车2和实车3的数据进行训练、验证和测试。本文对每辆车的容量数据进行划分,50%作为训练集,其余50%作为测试集。每组试验均利用本文提出的混合模型、长短期记忆网络(Long short term memory, LSTM)、SVM和反向传播(Back propagation, BP)神经网络来预测,其中,实车1具体的预测曲线如图5 所示,对应的绝对误差曲线如图6 所示。为了便于比较3种预测结果的效果,计算得到的RMSE、MAE和MAPE如表1 所示。
图5
图6
从图5 可以看到,LSTM模型对于实车1容量衰减预测的误差较大,无法进行很好的预测,SVM模型的预测值与真实值较为接近,但是在容量变化较大的里程为410~420 km的部分,预测误差较大,也无法进行很好的预测,而所提混合模型同时预测容量的长期退化趋势和短期波动趋势,有效地消除了波动较大的数据对结果的影响。从表1 的对比结果也可知,混合模型具有更好的预测效果。
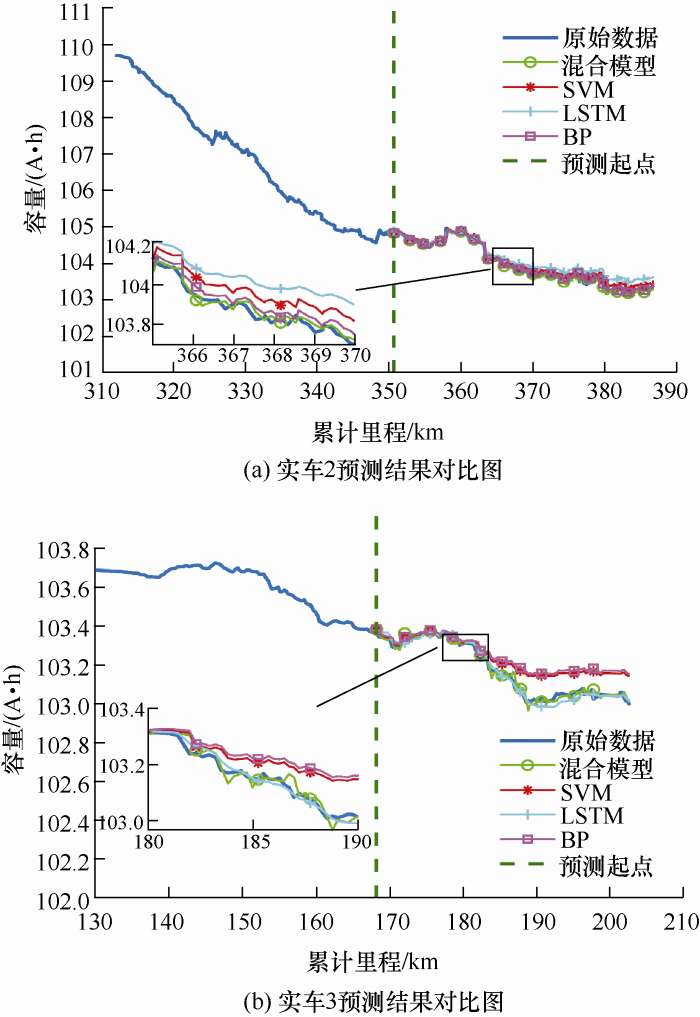
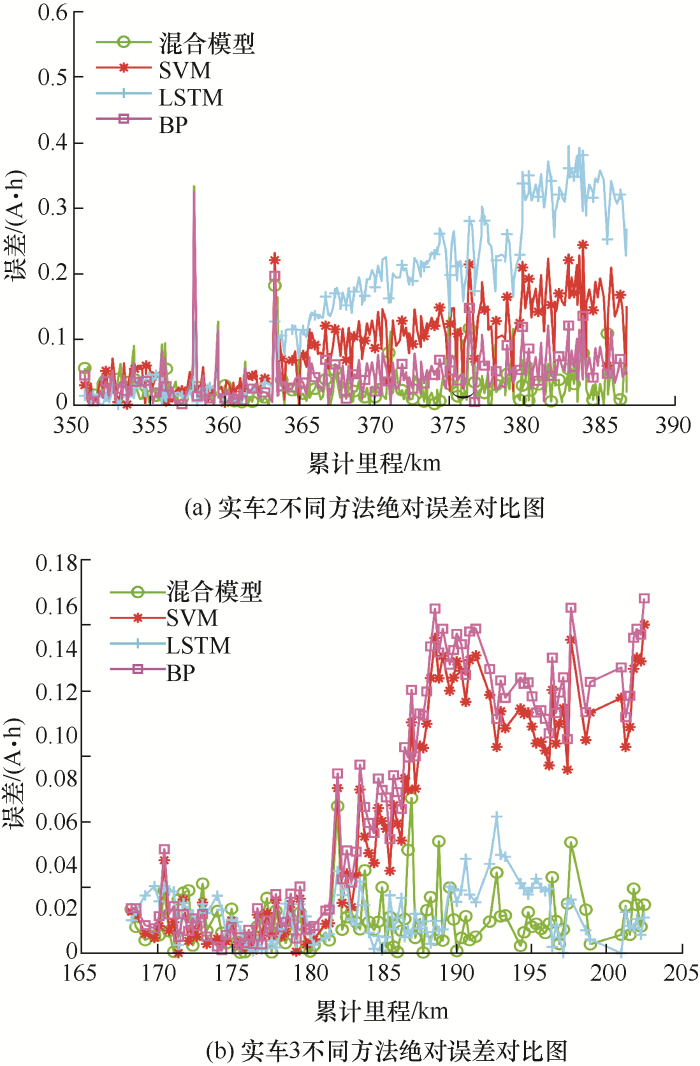
实车2、实车3的容量衰减预测结果及绝对误差对比如图7 、图8 所示,可以看出本文所提模型均优于传统的模型。
图7
图8
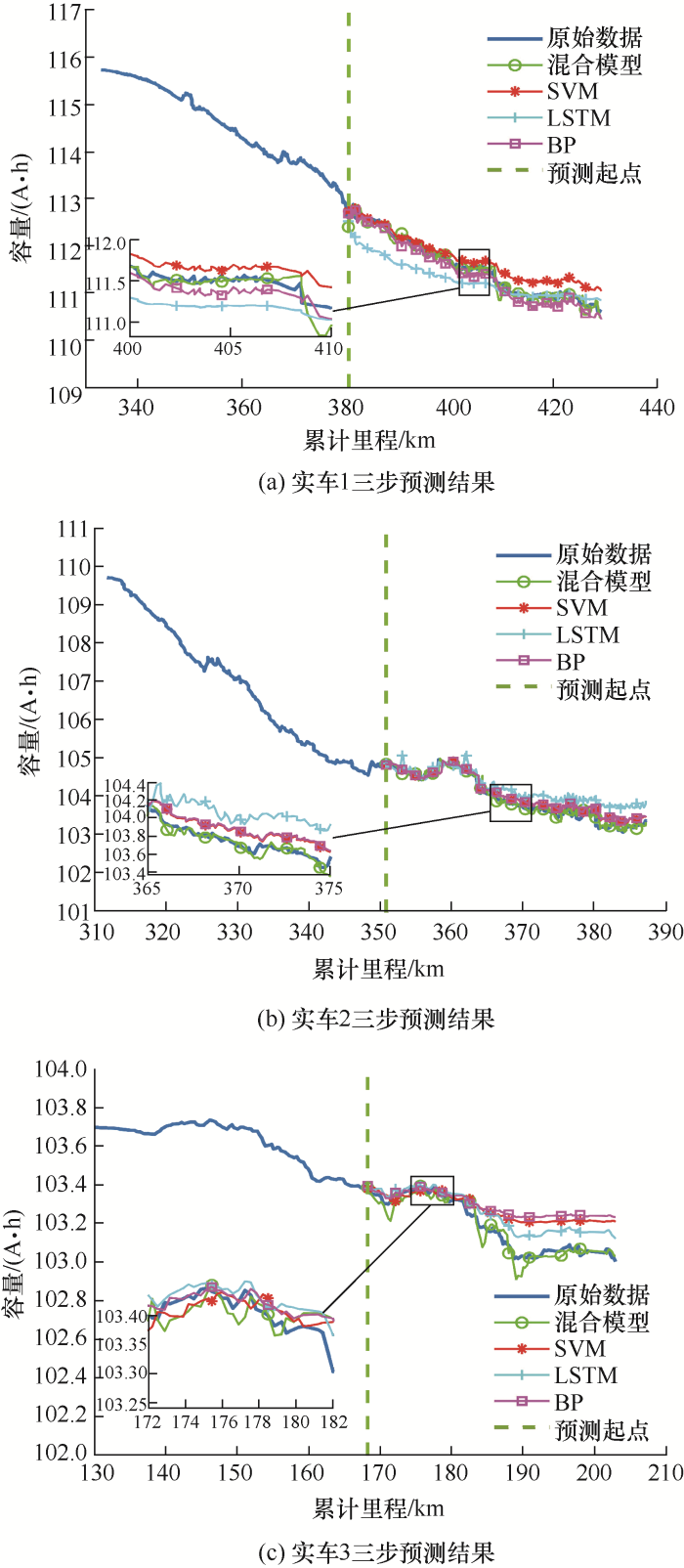
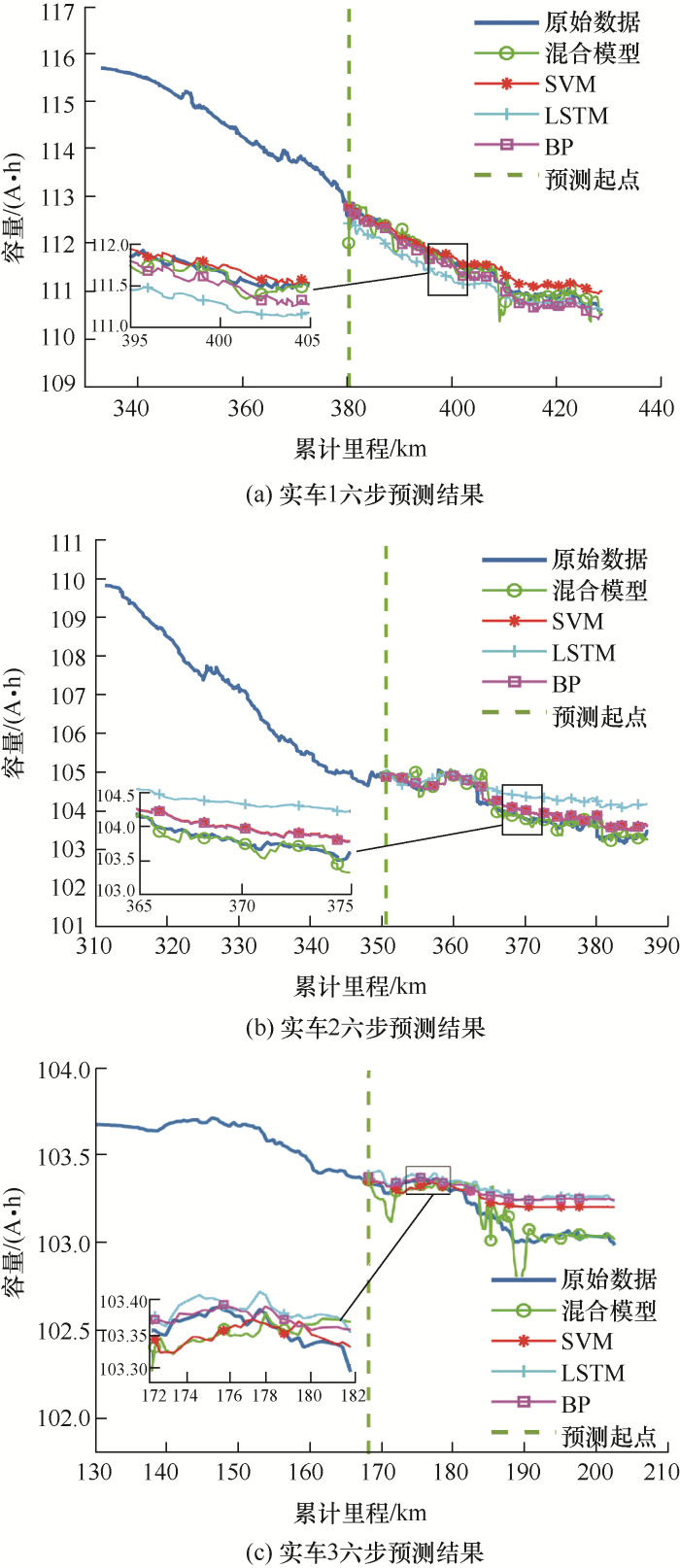
为了进一步展示所提方法的优势,图9 、10 展示了三辆车多步预测的结果,从表2 所提供的精度数据来看,本文提出的混合模型具有明显的优势,在大多数情况下预测效果都优于其他传统模型,即使在实车1和2的六步预测中,在RMSE参数上SVM击败了本文所提模型,但这两种方法之间的性能差异也非常小,可以忽略不计。而出现这种现象可能是由于均方根误差会对大误差进行平方,使大误差对整体误差的贡献更大,而平均绝对误差和平均绝对百分比误差只考虑误差本身,会导致大误差和小误差对整体的贡献度相同,而所提混合模型在进行六步预测时虽然正确度好,但是精密度稍差,所以导致RMSE参数上表现不如SVM好。此外,三步预测和六步预测的结果通常不如单步预测的结果准确,这是因为多步预测误差会随着步数的增加而累积,并且随着预测步数的增加,捕捉容量的变化趋势变得更加困难,导致预测难度变大,但是本文所提模型依然在大部分时候都优于其他模型,更加证明了其优越性能。
图9
图10
此外,在实际应用中,某些情况下需要用尽可能少的历史数据去预测未来的容量退化曲线,因此图11 和表3 研究了当训练集减少为30%时不同模型的预测能力。从图11 可以看出,所提融合模型在30%训练集时表现均好于传统模型,这表明所提融合模型只需要有限的历史数据就能给出可靠的结果,且减少训练集个数对算法的RMSE、MAE、MAPE影响较小,这表明较长的数据序列并不一定提高模型的性能,即不需要太多的历史数据便可以保证预测结果的稳定和准确。
图11
5 结论
本文研究了基于支持向量机与改进高斯过程混合模型的车用电池容量预测方法。主要的工作和结论如下所述。
(1) 针对电动汽车实车数据,利用安时积分法计算电池的容量,其中针对数据精度低的情况,对SOC数据进行插值处理,然后利用EEMD分解对容量数据进行分解。
(2) 利用支持向量机对分解后的容量长期退化趋势进行建模预测,利用改进的高斯过程对分解后的短期波动部分进行建模预测,最后将两者相加得到最终的容量预测结果。
(3) 基于三辆实车数据集的试验结果表明,均方根误差(RMSE)和平均绝对误差(MAE)分别为0.042 4和0.031 4,表明本文提出的方法能够适用于实车数据的容量预测。
参考文献
View Option
[1]
赵振利 . 电动汽车私桩共享充电定价模型及效益分配研究 [D]. 北京 : 华北电力大学 , 2020 .
[本文引用: 1]
ZHAO Zhenli Study on pricing model and benefit distribution of charging pile sharing for electric vehicles [D]. Beijing : North China Electric Power University , 2020 .
[本文引用: 1]
[2]
KIM I L S A technique for estimating the state of health of lithium batteries through a dual-sliding-mode observer
[J]. IEEE Transactions on Power Electronics , 2009 , 25 (4 ):1013 -1022 .
DOI:10.1109/TPEL.2009.2034966
URL
[本文引用: 1]
[3]
耿星 , 王友仁 . 蓄电池SOH估算方法研究综述
[J]. 机械制造与自动化 , 2019 , 48 (1 ):210 -212 .
[本文引用: 1]
GENG Xing WANG Youren Review of SOH estimation method for battery
[J]. Mechanical Manufacturing and Automation , 2019 , 48 (1 ):210 -212 .
[本文引用: 1]
[4]
HASHEMI S R MAHAJAN A M FARHAD S Online estimation of battery model parameters and state of health in electric and hybrid aircraft application
[J]. Energy , 2021 , 229 (1 ):120699 .
DOI:10.1016/j.energy.2021.120699
URL
[本文引用: 1]
[5]
ZHOU L YANG Z LI D et al. State-of-health estimation for LiFePO4 battery system on real-world electric vehicles considering aging stage
[J]. IEEE Transactions on Transportation Electrification , 2021 , 8 (2 ):1724 -1733 .
DOI:10.1109/TTE.2021.3129497
URL
[本文引用: 1]
[6]
周頔 , 宋显华 , 卢文斌 , 等 . 基于日常片段充电数据的锂电池健康状态实时评估方法研究
[J]. 中国电机工程学报 , 2019 , 39 (1 ):107 -113 ,327.
[本文引用: 2]
ZHOU Di SONG Xianhua LU Wenbin et al. Real-time SOH estimation algorithm for lithium-ion batteries based on daily segment charging data
[J]. Proceedings of the CSEE , 2019 , 39 (1 ):107 -113 ,327.
[本文引用: 2]
[7]
DRISCOLL L De La TORRE S GOMEZ-RUIZ J A Feature-based lithium-ion battery state of health estimation with artificial neural networks
[J]. Journal of Energy Storage , 2022 ,50:104584.
[本文引用: 2]
[8]
DUAN W SONG S XIAO F et al. Battery SOH estimation and RUL prediction framework based on variable forgetting factor online sequential extreme learning machine and particle filter
[J]. Journal of Energy Storage , 2023 ,65:107322.
[本文引用: 2]
[9]
张新锋 , 姚蒙蒙 , 王钟毅 , 等 . 基于ACO-BP神经网络的锂离子电池容量衰退预测
[J]. 储能科学与技术 , 2020 , 9 (1 ):138 -144 .
DOI:10.19799/j.cnki.2095-4239.2019.0190
[本文引用: 2]
准确预测电池的容量衰退趋势对加强电池系统的管理和维护具有重要意义。本工作选择以锂离子电池为研究对象,根据NASA实验室公开的源数据集分析、预测锂离子电池的容量衰退趋势。在室温、恒流工况下对锂离子电池进行满充满放的循环充放电试验,得到各循环周期下电池的实际额定容量值,采用紧支集正交小波分析对获得的电池监测数据进行去噪优化处理,得到更加平稳规律的电池容量衰退过程,然后利用蚁群算法(Ant colony optimization,ACO)优化BP神经网络的初始权值和阈值,基于ACO-BP神经网络模型完成对锂离子电池容量衰退的预测,并与单独使用BP神经网络进行对比。结果表明,采用ACO-BP神经网络比单独使用BP神经网络具有更好的预测效果,且随着训练样本的增加,包含更多的电池容量退化信息,预测精度明显提高,当以前80个循环充放电周期作为训练样本时,预测的平均误差为1.46%,若继续扩大训练样本,预测效果将会更好。本研究有助于加强电池系统的健康管理,为高效预测锂离子电池的劣化轨迹提供技术参考。
ZHANG Xinfeng YAO Mengmeng WANG Zhongyi et al. Lithium-ion battery capacity decline prediction based on ant colony optimization BP neural network algorithm
[J]. Energy Storage Science and Technology , 2020 , 9 (1 ):138 -144 .
DOI:10.19799/j.cnki.2095-4239.2019.0190
[本文引用: 2]
Accurately predicting the declining trend with respect to the capacity of a battery is important for strengthening the management and maintenance of the battery system. Lithium-ion batteries are the research object; the battery capacity decline trend is predicted based on a source data set analysis published by NASA Laboratories. The data for a full-cycle charge-discharge test of a battery, obtained at room temperature and constant current, are denoised and optimized by a compact set orthogonal wavelet analysis to obtain a more stable and regular battery capacity decay process. The ant colony optimization (ACO) algorithm is subsequently used to optimize the initial weight of the BP neural network. And threshold, based on the ACO-BP neural network model to predict the capacity decline of lithium-ion batteries, and compared with BP neural network alone. The results denote that the ACO-BP neural network generates better prediction results when compared with that generated by the BP neural network alone; with more training samples, it contains more information on battery capacity degradation, and the prediction accuracy is significantly improved. The predicted average error is 1.46% when 80 charge and discharge cycles are used as training samples. If the training samples are further expanded, the prediction effect will improve. This study helps to strengthen the management of the battery systems and provides a technical reference for efficiently predicting the degradation trajectory of the lithium-ion batteries.
[10]
CHENG G WANG X HE Y Remaining useful life and state of health prediction for lithium batteries based on empirical mode decomposition and a long and short memory neural network
[J]. Energy , 2021 ,232:121022.
[本文引用: 2]
[11]
JIA J LIANG J SHI Y et al. SOH and RUL prediction of lithium-ion batteries based on Gaussian process regression with indirect health indicators
[J]. Energy , 2020 , 13 (2 ):375 .
[本文引用: 1]
[12]
范智伟 , 乔丹 , 崔海港 . 锂离子电池充放电倍率对容量衰减影响研究
[J]. 电源技术 , 2020 , 44 (3 ):325 -329 .
[本文引用: 1]
FAN Zhiwei QIAO Dan CUI Haigang Research on the effect of charge and discharge rates on capacity fading of lithium-ion batteries
[J]. Journal of Power Sources , 2020 , 44 (3 ):325 -329 .
[本文引用: 1]
[13]
武佳卉 , 邵振国 , 杨少华 , 等 . 数据清洗在新能源功率预测中的研究综述和展望
[J]. 电气技术 , 2020 , 21 (11 ):1 -6 .
[本文引用: 1]
WU Jiahui SHAO Zhenguo YANG Shaohua et al. Review and prospect of data cleaning in renewable energy power prediction
[J]. Electrical Engineering , 2020 , 21 (11 ):1 -6 .
[本文引用: 1]
[14]
胡杰 , 何陈 , 朱雪玲 , 等 . 基于实车数据的电动汽车电池剩余使用寿命预测
[J]. 交通运输系统工程与信息 , 2022 , 22 (1 ):292 -300 .
[本文引用: 1]
HU Jie HE Chen ZHU Xueling et al. Predicting remaining useful life of electric vehicle battery based on real vehicle data
[J]. Journal of Transportation Systems Engineering and Information Technology , 2022 , 22 (1 ):292 -300 .
[本文引用: 1]
[15]
杨心月 , 荆博 , 梅志刚 , 等 . 风电机组功率异常数据剔除方法研究
[J/OL]. 电测与仪表 :1 -9 [2024-01-25]. http://kns.cnki.net/kcms/detail/23.1202.TH.20221025.1809.006.html.
URL
[本文引用: 1]
YANG Xinyue JING Bo MEI Zhigang et al. Methods for elimination of abnormal power data of wind turbine
[J/OL]. Electrical Measurement and Instrumentation :1 -9 [2024-01-25]. http://kns.cnki.net/kcms/detail/23.1202.TH.20221025.1809.006.html.
URL
[本文引用: 1]
[16]
LI Q LI R JI K et al. Kalman filter and its application
[C]// 2015 8th International Conference on Intelligent Networks and Intelligent Systems (ICINIS),Tianjin,China,2015: 74 -77 .
[本文引用: 1]
[17]
WU Zhaohua HUANG N E Ensemble empirical mode decomposition:A noise-assisted data analysis method
[J]. Advances in Adaptive Data Analysis , 2009 , 1 (1 ):1 -41 .
DOI:10.1142/S1793536909000047
URL
[本文引用: 1]
A new Ensemble Empirical Mode Decomposition (EEMD) is presented. This new approach consists of sifting an ensemble of white noise-added signal (data) and treats the mean as the final true result. Finite, not infinitesimal, amplitude white noise is necessary to force the ensemble to exhaust all possible solutions in the sifting process, thus making the different scale signals to collate in the proper intrinsic mode functions (IMF) dictated by the dyadic filter banks. As EEMD is a time–space analysis method, the added white noise is averaged out with sufficient number of trials; the only persistent part that survives the averaging process is the component of the signal (original data), which is then treated as the true and more physical meaningful answer. The effect of the added white noise is to provide a uniform reference frame in the time–frequency space; therefore, the added noise collates the portion of the signal of comparable scale in one IMF. With this ensemble mean, one can separate scales naturally without any a priori subjective criterion selection as in the intermittence test for the original EMD algorithm. This new approach utilizes the full advantage of the statistical characteristics of white noise to perturb the signal in its true solution neighborhood, and to cancel itself out after serving its purpose; therefore, it represents a substantial improvement over the original EMD and is a truly noise-assisted data analysis (NADA) method.
[18]
OTCHERE D A GANAT T O A GHOLAMI R et al. Application of supervised machine learning paradigms in the prediction of petroleum reservoir properties:Comparative analysis of ANN and SVM models
[J]. Journal of Petroleum Science and Engineering , 2021 ,200:108182.
[本文引用: 1]
[19]
LI L WANG P CHAO K-H et al. Remaining useful life prediction for lithium-ion batteries based on Gaussian processes mixture
[J]. PloS One , 2016 , 11 (9 ):e0163004 .
DOI:10.1371/journal.pone.0163004
URL
[本文引用: 1]
[20]
ZHU M OUYANG Q WAN Y et al. Remaining useful life prediction of lithium-ion batteries:A hybrid approach of grey-Markov chain model and improved Gaussian process
[J]. IEEE Journal of Emerging and Selected Topics in Power Electronics , 2023 , 11 (1 ):143 -153 .
DOI:10.1109/JESTPE.2021.3098378
URL
[本文引用: 1]
1
2020
... 近年来,在全球实现“双碳”目标的背景下,新能源汽车的发展有助于减少温室气体的排放、改善生态坏境,因而得到了全球各国的重视.而随着新一轮科技革命和产业变革的兴起,我国的新能源汽车产业也进入了加速发展的阶段[1 ] .电动汽车电池的容量会随着充放电循环次数的增加而衰减,因此,对于电池容量的准确预测有助于为电池在使用寿命结束之前的更换提供指导,对提升用户的使用体验格外重要[2 ] . ...
1
2020
... 近年来,在全球实现“双碳”目标的背景下,新能源汽车的发展有助于减少温室气体的排放、改善生态坏境,因而得到了全球各国的重视.而随着新一轮科技革命和产业变革的兴起,我国的新能源汽车产业也进入了加速发展的阶段[1 ] .电动汽车电池的容量会随着充放电循环次数的增加而衰减,因此,对于电池容量的准确预测有助于为电池在使用寿命结束之前的更换提供指导,对提升用户的使用体验格外重要[2 ] . ...
A technique for estimating the state of health of lithium batteries through a dual-sliding-mode observer
1
2009
... 近年来,在全球实现“双碳”目标的背景下,新能源汽车的发展有助于减少温室气体的排放、改善生态坏境,因而得到了全球各国的重视.而随着新一轮科技革命和产业变革的兴起,我国的新能源汽车产业也进入了加速发展的阶段[1 ] .电动汽车电池的容量会随着充放电循环次数的增加而衰减,因此,对于电池容量的准确预测有助于为电池在使用寿命结束之前的更换提供指导,对提升用户的使用体验格外重要[2 ] . ...
蓄电池SOH估算方法研究综述
1
2019
... 目前,电池容量估计的方法主要包括直接测量法、基于模型的方法和基于数据驱动的方法三类.直接测量法是在实验室条件下对电池的开路电压、充放电电流、内阻等指标进行离线测量,然后再通过相应的公式等计算电池的容量.这种方法计算简单且容易实现,但是需要将目标电池从电动汽车上取下来,难以用于计算工作状态下的动力电池的容量[3 ] .基于模型的方法依赖于寿命衰减模型、经验模型和等效电路模型,通过搭建空间状态模型表征电池内部电化学机理,然后利用非线性状态估计器或者自适应滤波等更新参数来进行电池容量的估计[4 ] .但是,现有的基于电化学模型方法在试验过程中需要特定的设备来获取锂离子电池的内部机构,检测时间过长,效率较低,无法满足容量预测的要求[5 ] . ...
Review of SOH estimation method for battery
1
2019
... 目前,电池容量估计的方法主要包括直接测量法、基于模型的方法和基于数据驱动的方法三类.直接测量法是在实验室条件下对电池的开路电压、充放电电流、内阻等指标进行离线测量,然后再通过相应的公式等计算电池的容量.这种方法计算简单且容易实现,但是需要将目标电池从电动汽车上取下来,难以用于计算工作状态下的动力电池的容量[3 ] .基于模型的方法依赖于寿命衰减模型、经验模型和等效电路模型,通过搭建空间状态模型表征电池内部电化学机理,然后利用非线性状态估计器或者自适应滤波等更新参数来进行电池容量的估计[4 ] .但是,现有的基于电化学模型方法在试验过程中需要特定的设备来获取锂离子电池的内部机构,检测时间过长,效率较低,无法满足容量预测的要求[5 ] . ...
Online estimation of battery model parameters and state of health in electric and hybrid aircraft application
1
2021
... 目前,电池容量估计的方法主要包括直接测量法、基于模型的方法和基于数据驱动的方法三类.直接测量法是在实验室条件下对电池的开路电压、充放电电流、内阻等指标进行离线测量,然后再通过相应的公式等计算电池的容量.这种方法计算简单且容易实现,但是需要将目标电池从电动汽车上取下来,难以用于计算工作状态下的动力电池的容量[3 ] .基于模型的方法依赖于寿命衰减模型、经验模型和等效电路模型,通过搭建空间状态模型表征电池内部电化学机理,然后利用非线性状态估计器或者自适应滤波等更新参数来进行电池容量的估计[4 ] .但是,现有的基于电化学模型方法在试验过程中需要特定的设备来获取锂离子电池的内部机构,检测时间过长,效率较低,无法满足容量预测的要求[5 ] . ...
State-of-health estimation for LiFePO4 battery system on real-world electric vehicles considering aging stage
1
2021
... 目前,电池容量估计的方法主要包括直接测量法、基于模型的方法和基于数据驱动的方法三类.直接测量法是在实验室条件下对电池的开路电压、充放电电流、内阻等指标进行离线测量,然后再通过相应的公式等计算电池的容量.这种方法计算简单且容易实现,但是需要将目标电池从电动汽车上取下来,难以用于计算工作状态下的动力电池的容量[3 ] .基于模型的方法依赖于寿命衰减模型、经验模型和等效电路模型,通过搭建空间状态模型表征电池内部电化学机理,然后利用非线性状态估计器或者自适应滤波等更新参数来进行电池容量的估计[4 ] .但是,现有的基于电化学模型方法在试验过程中需要特定的设备来获取锂离子电池的内部机构,检测时间过长,效率较低,无法满足容量预测的要求[5 ] . ...
基于日常片段充电数据的锂电池健康状态实时评估方法研究
2
2019
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Real-time SOH estimation algorithm for lithium-ion batteries based on daily segment charging data
2
2019
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Feature-based lithium-ion battery state of health estimation with artificial neural networks
2
2022
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Battery SOH estimation and RUL prediction framework based on variable forgetting factor online sequential extreme learning machine and particle filter
2
2023
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
基于ACO-BP神经网络的锂离子电池容量衰退预测
2
2020
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Lithium-ion battery capacity decline prediction based on ant colony optimization BP neural network algorithm
2
2020
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Remaining useful life and state of health prediction for lithium batteries based on empirical mode decomposition and a long and short memory neural network
2
2021
... 基于数据驱动的方法不需要对电池内部复杂的电化学机理进行精确建模,也无需进行电池自身参数的辨识,而是通过对历史的电池电流、电压和温度等参数进行分析,提取与容量变化高度相关的特征,并将其作为训练数据构建估计模型,从而得到对于容量的预测结果[6 ] .文献[7 ]对从充电过程中电压、电流和温度分布模式中观察到的特征进行提取,然后通过人工神经网络进行每个周期的估计;文献[8 ]采用可变遗忘因子在线顺序极限学习机估计电池容量,并采用一种新的非线性衰落法、自适应权值法的高斯变分法对标准鲸鱼优化算法进行了改进,并将改进后的算法用于算法的优化.文献[9 ]利用紧支集正交小波分析对试验得到的电池额定容量数据进行去噪优化处理,然后利用蚁群算法对反向传播神经网络的初始权值和阈值进行优化,从而预测电池容量退化信息;文献[10 ]将经验模态分解方法和反向传播长短期记忆神经网络相结合,建立了容量预测模型,有效提高了预测精度. ...
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
SOH and RUL prediction of lithium-ion batteries based on Gaussian process regression with indirect health indicators
1
2020
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
锂离子电池充放电倍率对容量衰减影响研究
1
2020
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
Research on the effect of charge and discharge rates on capacity fading of lithium-ion batteries
1
2020
... 然而,上述文献[6 ⇓ ⇓ ⇓ ⇓ -11 ]中方法的数据来源于实验室,其有效性依赖于实验室数据的采样精度和计算精度,当数据质量较差时,这些方法的准确性将会下降.此外,这些方法的验证数据通常是在恒定电流、恒定温度的实验室环境中测量,但是在电动汽车实际运行过程中,电池的寿命受到很多其他因素的影响,如使用模式、驾驶特性等[12 ] ,这导致电动汽车电池在生命周期中表现出容量长期的衰减趋势和短期的波动现象.因此利用实际的数据进行容量预测的难度较大.此外,目前的研究对于容量退化轨迹的预测大多是以电池充放电循环次数作为自变量来描述电池容量衰减的过程,但是在运用到实际车辆时,使用行驶里程作为自变量能为驾驶员提供参考,更具有现实意义. ...
数据清洗在新能源功率预测中的研究综述和展望
1
2020
... 本文选择新能源汽车国家大数据联盟提供的3辆新能源汽车近1年的实时运行数据进行车用电池容量分析和预测,其中数据集包含电池电压、电池电流、累计里程、充电状态等40个参数,采样间隔为10 s.由于实车数据在传输过程中存在信号延迟、错报甚至丢失的情况,造成累积里程跳变、数据波动较大等数据异常,因此首先采用基于3-$\sigma $ [13 ] 等数据预处理方法,以剔除掉原始数据集中异常和离群数据.图1 展示了原始数据预处理的总体流程. ...
Review and prospect of data cleaning in renewable energy power prediction
1
2020
... 本文选择新能源汽车国家大数据联盟提供的3辆新能源汽车近1年的实时运行数据进行车用电池容量分析和预测,其中数据集包含电池电压、电池电流、累计里程、充电状态等40个参数,采样间隔为10 s.由于实车数据在传输过程中存在信号延迟、错报甚至丢失的情况,造成累积里程跳变、数据波动较大等数据异常,因此首先采用基于3-$\sigma $ [13 ] 等数据预处理方法,以剔除掉原始数据集中异常和离群数据.图1 展示了原始数据预处理的总体流程. ...
基于实车数据的电动汽车电池剩余使用寿命预测
1
2022
... 对于每一个充电片段,为了减小由于采样时间跨度过大造成的误差,采用滑动窗口移动平均的方法来计算每个充电过程中的电动汽车电池容量大小[14 ] .从起点开始,以20个数据点为一个窗口,应用安时积分法计算该窗口的电池容量大小,然后依次滑动窗口至充电终点,最后计算所有窗口容量均值作为该充电过程电池容量.如式(2)所示 ...
Predicting remaining useful life of electric vehicle battery based on real vehicle data
1
2022
... 对于每一个充电片段,为了减小由于采样时间跨度过大造成的误差,采用滑动窗口移动平均的方法来计算每个充电过程中的电动汽车电池容量大小[14 ] .从起点开始,以20个数据点为一个窗口,应用安时积分法计算该窗口的电池容量大小,然后依次滑动窗口至充电终点,最后计算所有窗口容量均值作为该充电过程电池容量.如式(2)所示 ...
风电机组功率异常数据剔除方法研究
1
... 上述计算得到的容量值中,存在远离数据中心的离群点,这些离群点会影响后续模型的精度,因此需要剔除这部分异常数据.由于容量数据集中异常值具体信息未知且数据量较大,因此采用基于密度的聚类算法(Density-based spatial clustering of applications with noise, DBSCAN)来进行离群值的剔除[15 ] . ...
Methods for elimination of abnormal power data of wind turbine
1
... 上述计算得到的容量值中,存在远离数据中心的离群点,这些离群点会影响后续模型的精度,因此需要剔除这部分异常数据.由于容量数据集中异常值具体信息未知且数据量较大,因此采用基于密度的聚类算法(Density-based spatial clustering of applications with noise, DBSCAN)来进行离群值的剔除[15 ] . ...
Kalman filter and its application
1
... 卡尔曼滤波是一种高效的自回归滤波器,它能在存在诸多不确定情况的组合信息中估计动态系统的状态,适用于在含有不确定因素的动态线性系统里找到系统当前状态的最优解[16 ] .为了减少过程噪声和测量噪声对容量计算结果的影响,进一步提高容量计算精度,设计如下卡尔曼滤波器 ...
Ensemble empirical mode decomposition:A noise-assisted data analysis method
1
2009
... EEMD具有处理非平稳数据序列的能力,在EMD分解中,得到的IMF可能存在着模态混叠的现象,影响分解效果,在文献[17 ]中提出了一种新的EEMD方法来解决这个问题,高斯白噪声具有频率均匀分布的统计特性,而EEMD利用该特性通过每次加入同等幅值的不同白噪声来改变信号的极值点特性,之后对多次EMD得到的相应IMF进行总体平均来抵消加入的白噪声,从而有效抑制模态混叠的产生.EEMD分解之后,L 和F 作为两个部分在下一步中用于单独的模型训练. ...
Application of supervised machine learning paradigms in the prediction of petroleum reservoir properties:Comparative analysis of ANN and SVM models
1
2021
... 支持向量机模型以结构风险最小化为基础,利用回归方法来解决非线性问题[18 ] ,而电动汽车电池的容量受到很多因素的影响,如电流、放电深度和环境温度等,且这些影响因素与容量衰减之间并不是简单的线性关系,因此对于长期容量下降趋势,采用局部支持向量机模型来对其进行建模. ...
Remaining useful life prediction for lithium-ion batteries based on Gaussian processes mixture
1
2016
... 高斯回归过程是一种贝叶斯回归方法,其优点是只需要小数据集,并且是一种非参数回归模型.高斯回归过程已经广泛地用于电池的剩余寿命预测[19 ] ,MOMoGP[20 ] 是一种改进的多输出高斯过程算法,它可以准确捕捉输出维度之间的相关性,更好地利用高维空间预测容量的短期波动. ...
Remaining useful life prediction of lithium-ion batteries:A hybrid approach of grey-Markov chain model and improved Gaussian process
1
2023
... 高斯回归过程是一种贝叶斯回归方法,其优点是只需要小数据集,并且是一种非参数回归模型.高斯回归过程已经广泛地用于电池的剩余寿命预测[19 ] ,MOMoGP[20 ] 是一种改进的多输出高斯过程算法,它可以准确捕捉输出维度之间的相关性,更好地利用高维空间预测容量的短期波动. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}