1 引言
为了保证电网可靠性供电的目标,实现“零停电、零投诉”,电网需要通过“智能装备、智慧运行”的发展路径充分探索智能化手段在设备运维和故障诊断方面的可行策略,在运维人员定额不变的现有条件下全面提升变电设备管控能力[1 ] 。
在电力系统的运行中,高压隔离开关是使用场合极多的一次设备。其原理结构相对简单,但是绝大多数是在户外使用,在面临不同恶劣环境时,例如大雨、大雪、暴晒时可能会导致其出现各种不同的故障,这将会对电力系统的稳定运行造成影响。在隔离开关的缺陷大类中,主要分为操作机构轻微卡涩、操作机构严重卡涩、平衡弹簧失效、动触头合闸不到位[2 ] 等。随着新投入运变电站数量的与日俱增,隔离开关故障导致的电网非计划停运事故事件占比越来越高,直接影响到电厂的功率出力以及用户供电情况,严重影响了电网供电的可靠性及稳定性,对社会经济发展产生不良影响。文献[3 ]通过监测电机电流来获取电机机械状态特征量,同时研究特征量提取方法,建立机械故障诊断系统。
文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路。文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征。文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性。
上述方法性能依赖于大量含标记的训练样本,并且要求训练样本与测试样本具有相同的特征分布。将面临的是隔离开关故障试验数据量并没有达到高性能训练模型要求,使得训练时准确率高而投入运用时无法准确且高效地识别故障。
时间序列聚类算法是一种重要的数据挖掘技术,被广泛应用于基因组数据[7 ] 、异常检测[8 ] 以及任何需要模式监测的领域。时间序列聚类有助于发现有用的模式,使数据分析人员能从复杂和大规模的数据中提取有价值的信息[9 ] 。
基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成。该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] 。然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] 。在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征。然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] 。
本文通过使用sequence to sequence (seq2seq)模型学习时间序列聚类的非线性时间表示,然而由于缺乏标签,如何有效地引导学习过程,以生成特定聚类的表示与捕获时间序列的动态性、多尺度特征是一个亟待解决的问题。此外,seq2seq模型依赖于编码器的能力,因此还需要提高编码器对时间序列的聚类能力。
本文提出了一种基于自主认知的深度时序聚类模型(Autonomous-cognition deep temporal clustering representation model,AC-DTCR)对定子电流特征分析的高压隔离开关机构故障诊断新方法。一个具备自主认知的系统或模型被设计用于理解数据集中各个类别之间的差异和关系,以便进行更准确的预测或分类。它考虑到每个类别所具有的特定特征和属性,并利用这些特征来提高性能。
基于以上分析,针对所研究的问题,本文进行了如下研究。
(1) 提出AC-DTCR隔离开关故障诊断模型,是一种新的时间序列聚类的无监督时间表示学习模型,将时间重构和K-means目标相结合,将隔离开关故障电流时间序列变成聚类表示。
(2) 引入了半监督训练模型,其可以利用未标记的数据进行学习,使模型的准确率得到提高,增加自主感知模块,并针对编码器引入了一种辅助分类任务,以提高模型的故障诊断准确率。
2 故障类型及深度时序聚类算法
2.1 隔离开关故障分类
隔离开关主要工作场景位于户外,其工作环境决定了会产生各种各样的故障。而现有设备就存在锈蚀、卡涩、制造工艺不良等现象,影响设备的正常工作,为电网的正常运行带来了负面影响。本文对高压隔离开关的卡涩故障、弹簧失效、合闸不到位三种故障进行诊断。传动机构卡涩故障主要产生在机构连杆连接部分和连杆部分,由于隔离开关处于户外环境,连接部分容易发生锈蚀,连杆部分发生形变,从而导致传动机构卡涩不流畅;合闸不到位故障主要是由于物体阻碍合闸或齿轮啮合不良等因素导致;而弹簧失效主要是由于平衡弹簧工件锈蚀,也存在制造工艺缺陷的问题。
本文主要针对隔离开关在动作时发生故障的电机电流时序数据为研究对象,隔离开关在出现故障后,电流峰值会增大并会在不同位置出现。由于数据量小且现在聚类算法主要集中在有标记的训练样本,对样本要求高,为解决此类问题,将改进的深度时序聚类算法应用在隔离开关故障诊断模型当中。
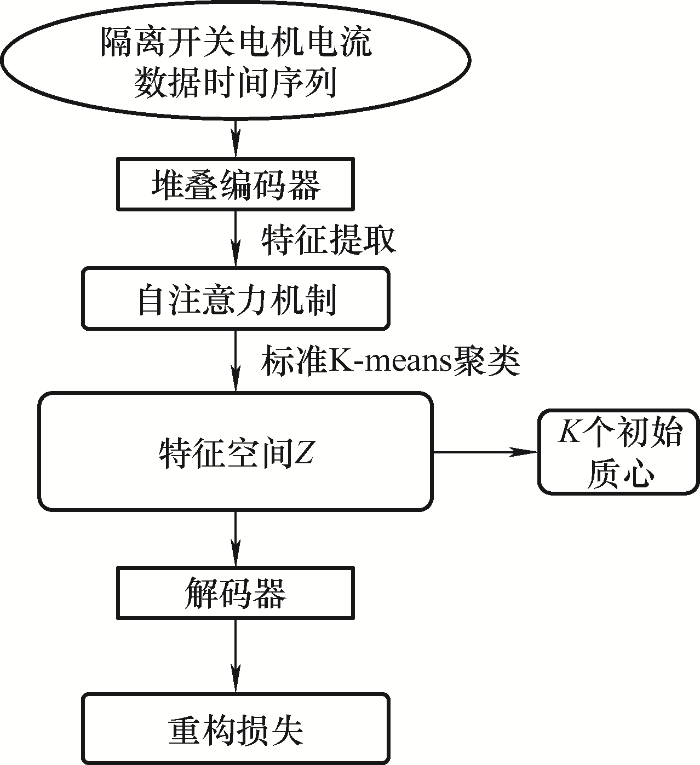
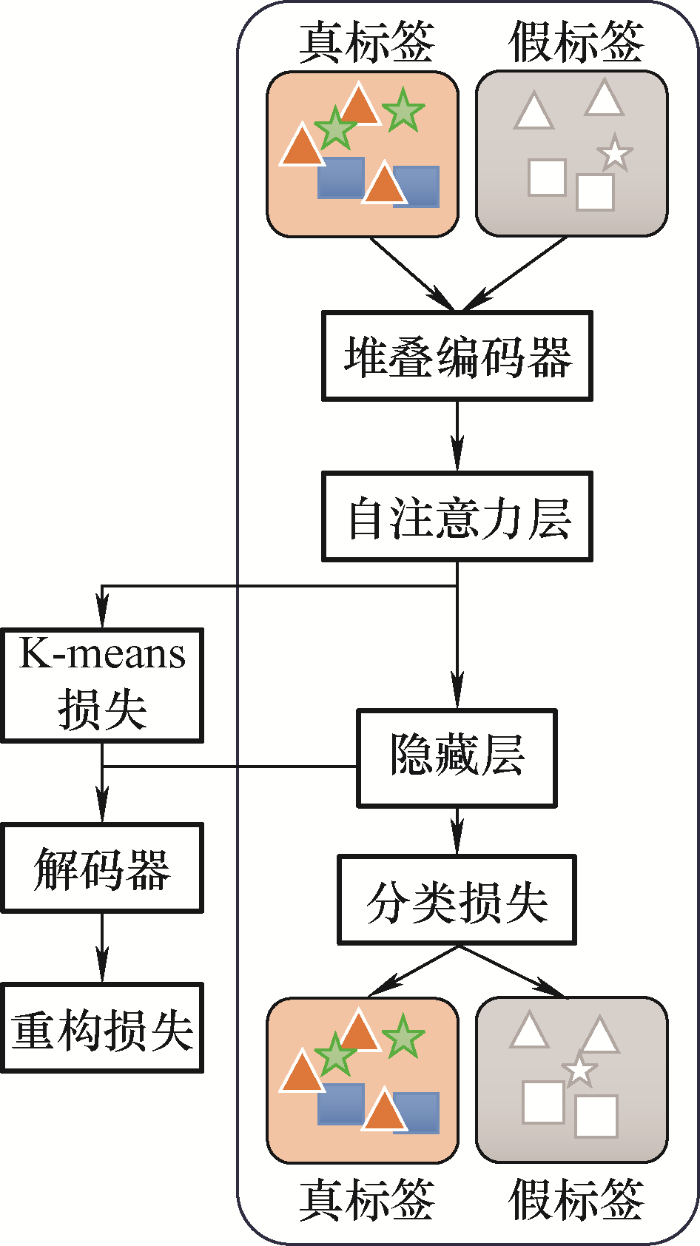
图1 为深度时序聚类(Deep temporal clustering representation,DTCR)算法的结构流程图。为了初始化聚类中心,本文将数据通过堆叠编码器初始化与自注意力层特征提取得到嵌入数据点,然后在特征空间Z 中进行标准K-means聚类,得到K 个初始质心。
图1
2.2 堆叠自编码-解码器
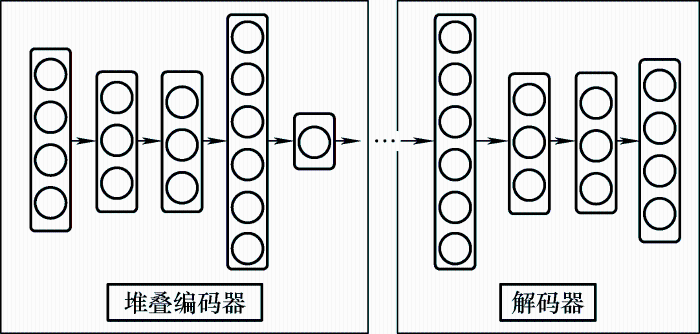
本文使用堆叠自编码器(Stacked auto-encoder,SAE)初始化DTCR,因为最近的研究表明它们在真实数据集上一致地产生语义有意义和分离的表示。因此,SAE学习到的无监督表示自然有利于DTCR聚类表示的学习。
本文采用的SAE是一个两层神经网络,每层都是一个去噪自编码器。通过逐层初始化SAE网络,训练可以重构上一层随机打乱后的输出,定义为
(1) $\tilde{x}\tilde{\ }Dropout(x)$
(2) $h={{g}_{1}}\left( {{W}_{1}}\tilde{x}+{{b}_{1}} \right)$
(3) $\tilde{h}\tilde{\ }Dropout(h)$
(4) $y={{g}_{2}}\left( {{W}_{2}}\tilde{h}+{{b}_{2}} \right)$
式中,$Dropout(\centerdot )$ ${{g}_{1}}$ ${{g}_{2}}$ $\theta =\left\{ {{W}_{1}},{{b}_{1}},{{W}_{2}},{{b}_{2}} \right\}$ $\left\| x-y \right\|_{2}^{2}$ h 作为输入训练下一层。除了第一对(需要重建可能有正负值的输入数据)的${{g}_{2}}$ ${{g}_{1}}$
在逐层训练之后,本文将所有编码器层和所有解码器层按照相反的逐层训练顺序串联起来,形成一个深度自编码器,然后对其进行微调以最小化重构损失。最终得到的结果是一个中间有瓶颈编码层的多层深度自编码器。使用编码器层作为数据空间和特征空间之间的初始映射,如图2 所示。
图2
2.3 自注意力层
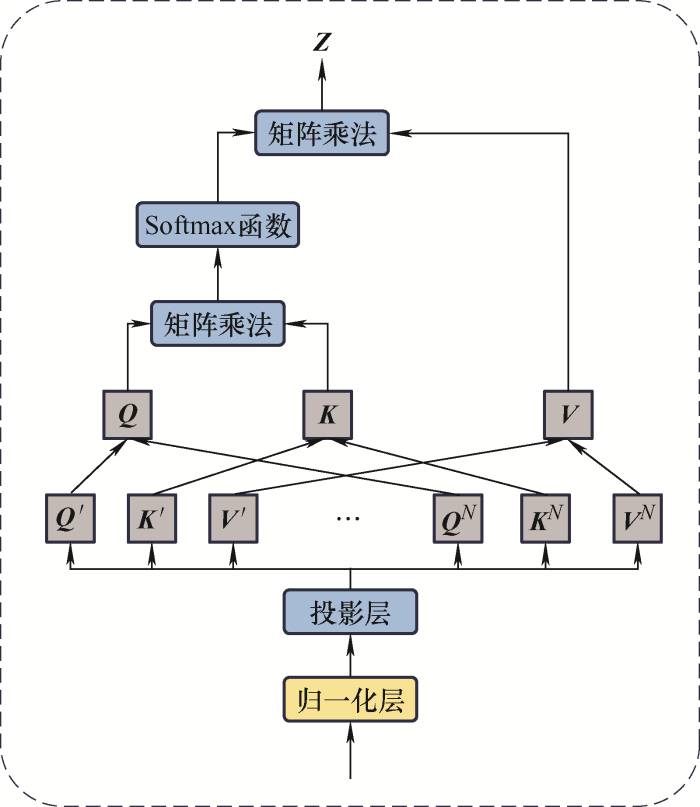
注意力机制是一种将可用计算资源的分配偏向信号中信息量最大部分的手段,不仅可以自动选择被关注部分,还可以自适应增强所关注部分。自注意力机制是将单个序列的不同位置相关联的注意力机制,通过关注同一序列中的所有位置,计算序列中每个位置的响应。自注意力机制的原理如图3 所示。
图3
首先,单个样本的N 个序列$[{{x}_{1}},{{x}_{2}},\cdots,{{x}_{N}}]$ d 的向量,${{q}^{i}},{{k}^{i}},{{v}^{i}}(i=1,\cdots,N)$ ${{q}^{i}},{{k}^{i}},{{v}^{i}}$ Q K V Q K $S=[{{S}_{1}},\cdots,{{S}_{N}}]$ S 为N 个序列间的权值集合;再根据式(6)获得标准化后的权值$S=[{{S}_{n1}},\cdots,{{S}_{nN}}]$
(5) $S=Q\cdot {{K}^{\text{T}}}$
(6) ${{S}_{n}}=\frac{S}{\sqrt{d}}$
然后,使用Softmax函数将权值转换成概率形式$P=[{{P}_{1}},\cdots,{{P}_{N}}]$
(7) ${{P}_{i}}=\operatorname{Softmax}\left( {{S}_{n}} \right)=\frac{{{e}^{{{S}_{ni}}}}}{\sum\limits_{i=1}^{N}{{{e}^{{{S}_{ni}}}}}}$
(8) ${{P}_{i}}=\frac{{{e}^{{{S}_{ni}}}}}{\sum{{{e}^{{{S}_{ni}}}}}}$
(9) $Z=V\cdot P$
注意力层计算局部窗口内的自注意力。窗口的排列以非重叠的方式均匀地划时间序列。假设有${{N}_{W}}$ ${{P}_{N}}$ $P={{P}_{N}}\times {{N}_{W}}$
(10) ${{A}_{w\text{ }}}(Q,K,V)=\left\{ A\left( {{Q}_{i}},{{K}_{i}},{{V}_{i}} \right) \right\}_{i=0}^{{{N}_{W}}}$
式中,${{Q}_{i}}{{K}_{i}}{{V}_{i}}$ $O(2P{{P}_{W}}C+4P{{C}^{2}})$ P 成线性复杂度。
2.4 K-means聚类
依据K-means聚类原理可以将聚类过程分为以下几个步骤。
步骤1:设置聚类的类簇个数为k ,最大迭代次数为N ,迭代终止阈值为$\delta $
步骤2:从数据集X 中给定一组m 维数据向量${{a}_{i}},i=1,\cdots,n$ $H=[{{a}_{1}},\cdots,{{a}_{n}}]$ $H\in {{R}^{m\times N}}$
步骤3:根据给定静态数据库矩阵$H\in {{R}^{m\times N}}$
${{L}_{K-means}}=\text{Tr(}{{H}^{\mathrm{T}}}H)-\text{Tr}({{F}^{\mathrm{T}}}{{H}^{\mathrm{T}}}HF)$
步骤5:重复上述迭代过程,直到聚类中心不再发生改变或者达到最大迭代次数停止迭代。
2.5 重构损失(Reconstruction loss)
本文使用均方误差(Mean square error,MSE)作为重构损失,其定义为
(11) ${{L}_{\text{reconstruction}}}=\frac{1}{n}\sum\limits_{i=1}^{n}{\left\| {{x}_{i}}-{{{\hat{x}}}_{i}} \right\|_{2}^{2}}$
式中,${{x}_{i}}$ ${{\hat{x}}_{i}}$ i 个样本的真实值和预测值,n 为样本个数。
MSE曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。此外,MSE随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。
2.6 深度时序聚类
给定n 个时间序列$D=\{{{x}_{1}},{{x}_{2}},\cdots,{{x}_{n}}\}$ ${{x}_{i}}$ T 个有序实值,记为${{x}_{i}}=({{x}_{i,1}},{{x}_{i,2}},\cdots,{{x}_{i,T}})$ ${{f}_{ens}}:{{x}_{i}}\to {{h}_{i}}$ ${{f}_{ens}}$ ${{h}_{i}}\in {{R}^{m}}$ m 维隐式表示,定义为
(12) ${{h}_{i}}={{f}_{ens}}\left( {{x}_{\mathbf{i}}} \right)$
本文旨在训练一个好的${{f}_{ens}}$
此外,考虑到时间序列通常是多尺度的,为学习到不同尺度的时间序列数据特征,因此采用自注意力层进行局部窗口学习。定义自适应线性映射${{f}_{Ada}}:{{h}_{i}}\to Q,K,V$ Z 提取过程为
(13) $Q,K,V={{f}_{Ada}}\left( {{h}_{i}} \right)$
(14) ${{Z}_{i}}=\operatorname{Attention}(Q,K,V)$
定义非线性映射${{f}_{dec}}:{{Z}_{i}}\to {{f}_{dec}}$
解码后可以得到输出${{\hat{x}}_{l}}$ ${{\hat{x}}_{l}}\in {{R}^{\mathrm{T}}}$
(15) ${{\hat{x}}_{i}}={{f}_{dec}}\left( {{z}_{i}} \right)$
使用均方误差${{L}_{reconstruction}}$
在给定静态数据矩阵$H\in {{R}^{m\times N}}$
(16) $\left\{ \begin{align} & {{L}_{K-\text{means }}}={{\max }_{F}}\operatorname{Tr}\left( {{F}^{\mathbf{T}}}{{H}^{\mathbf{T}}}HF \right) \\ & \text{s}\text{.t}\text{. }{{F}^{\mathbf{T}}}F=I \\ \end{align} \right.$
然而,在本文的案例中,H H $\lambda $
(17) $\left\{ \begin{align} & {{\min }_{H,F}}J(H)+\frac{\lambda }{2}\left[ \operatorname{Tr}\left( {{H}^{\mathrm{T}}}H \right)-\operatorname{Tr}\left( {{F}^{\mathrm{T}}}{{H}^{\mathrm{T}}}HF \right) \right] \\ & \text{s}\text{.t}\text{. }{{F}^{\mathrm{T}}}F=I \\ \end{align} \right.$
式中,$J(H)$ F H F H $\nabla J(H)+\gamma H(I-F{{F}^{T}})$ H F H F
3 半监督训练
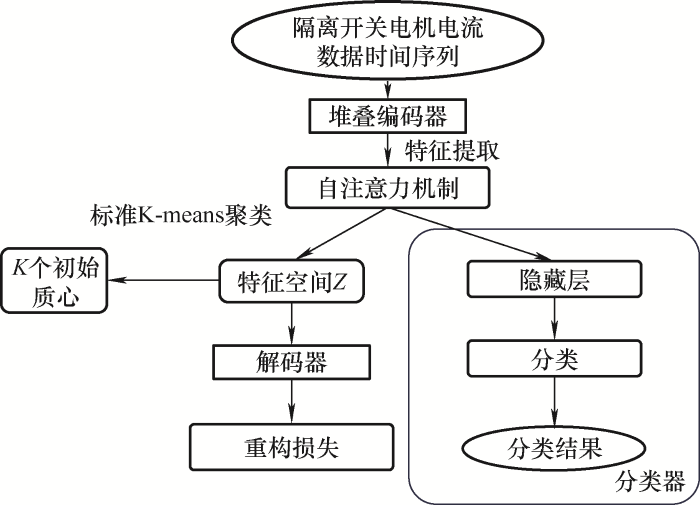
由于seq2seq模型依赖于编码器的能力,因此编码器训练得越好,学习到的表示就越好。对于时间序列,本文提出了伪样本生成策略和辅助分类任务组成半监督训练模型来增强编码器的能力,为完成上述任务,本文在DTCR基础上添加一个分类器(Autonomous-cognition),其总模型为AC-DTCR,架构如图4 所示。
图4
3.1 训练步骤
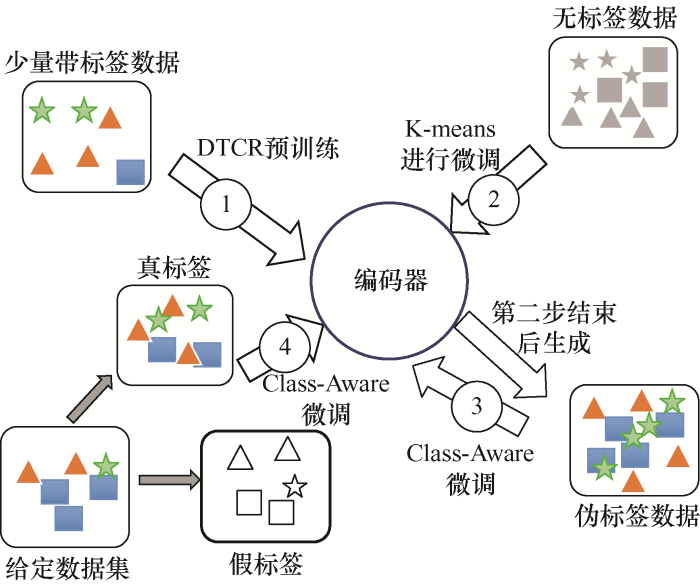
图5 是AC-DTCR模型训练步骤总图。从图5 可看出,训练步骤分为四步,分别通过DTCR、K-means、Autonomous-cognition等结构模型去训练模型来增强编码器的能力。
图5
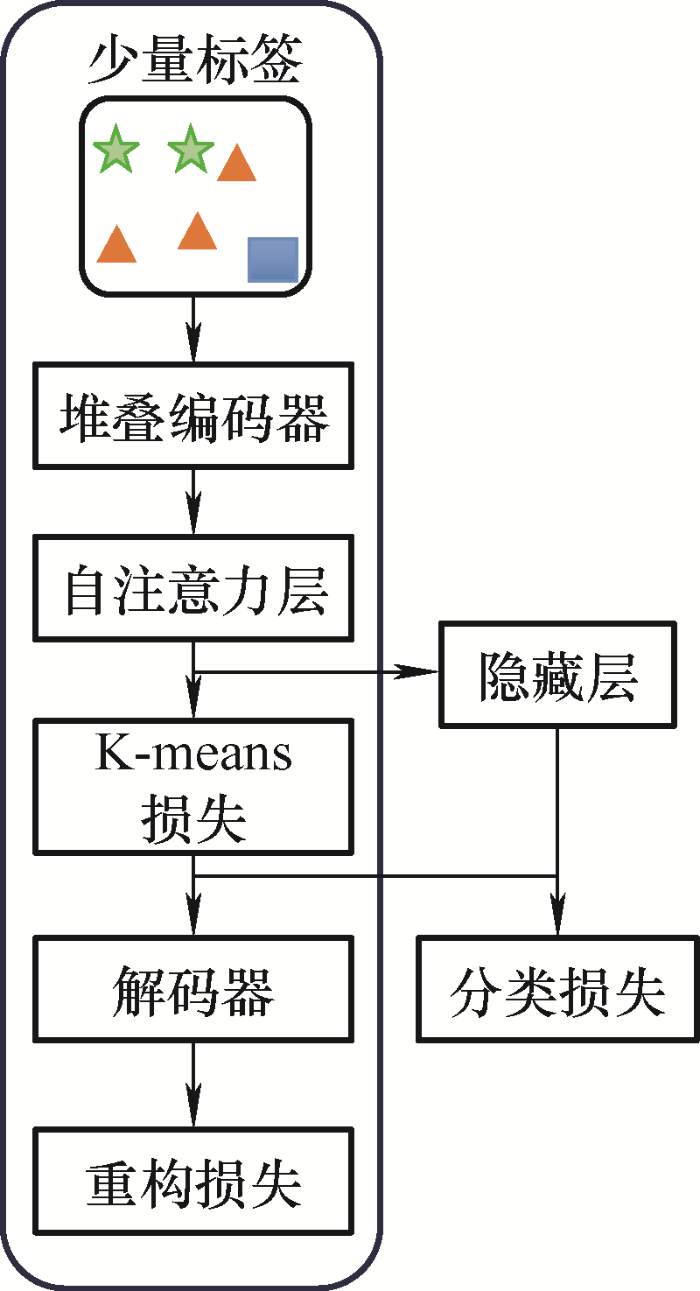
步骤1:使用上文提及的DTCR模型,通过少量已知的标注故障数据进行编码器预训练,进而调整编码器参数。在图6 中,本文冻结Autonomous-cognition模块仅仅用DTCR模块进行训练。
图6
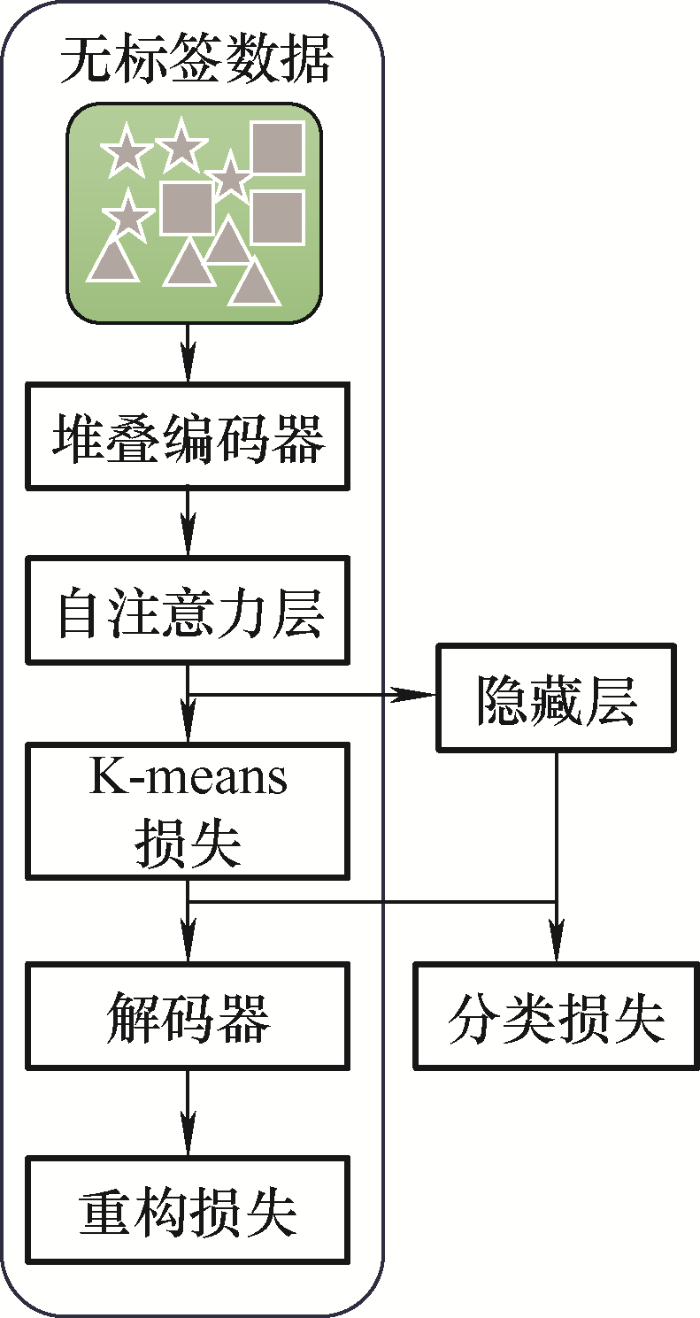
步骤2:在预训练好编码器模块后,本文使用K-means模块将部分无标签数据集进行训练,生成伪标签,也就是所提出来的伪标签生成策略。在图7 中本文冻结Autonomous-cognition模块与部分DTCR模块,仅仅使用K-means模块进行训练。
图7
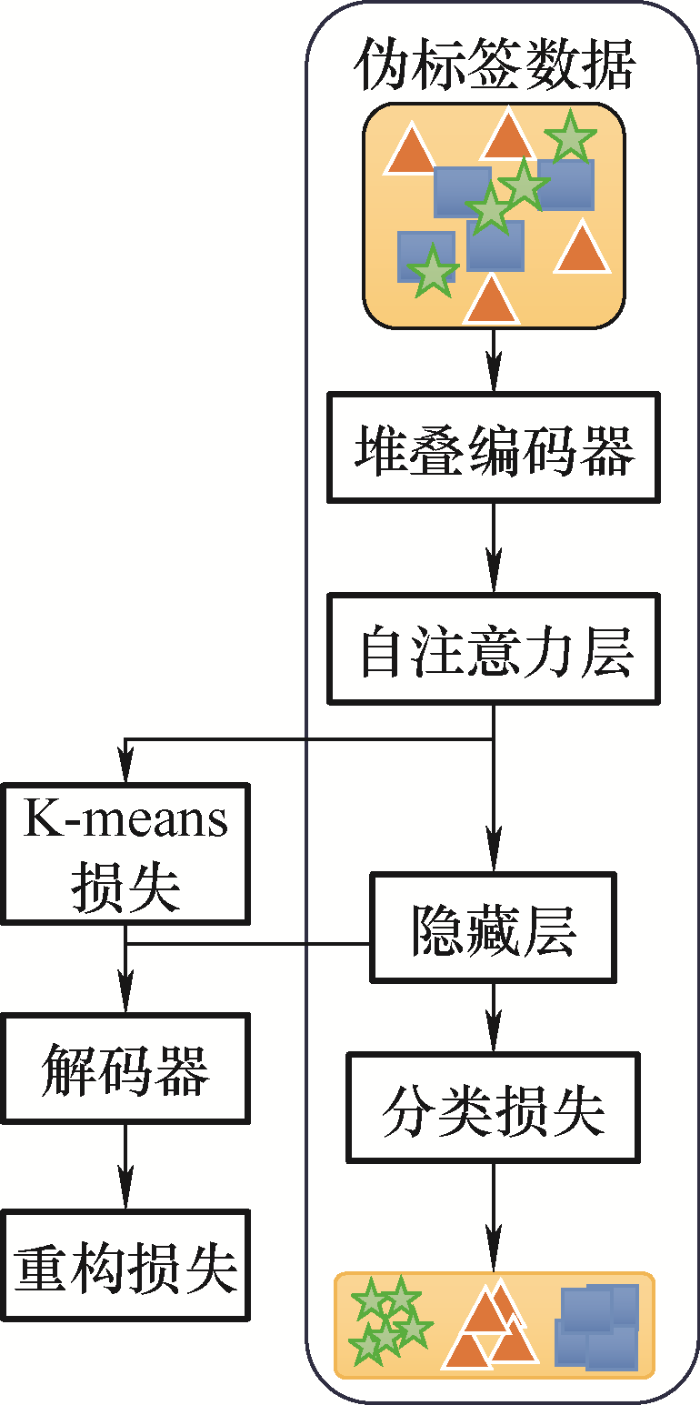
步骤3:在得到训练所得伪标签后,本文使用Autonomous-cognition模块对伪标签数据集进行训练,训练过程中也是进一步对编码器进行微调的过程。在图8 中本文冻结部分DTCR模块,使用Autonomous-cognition模块进行训练。
图8
Autonomous-cognition模块中,编码器是通过最小化以下损失函数来训练的
(18) ${{\hat{y}}_{i}}={{W}_{fc2}}\left( {{W}_{fc1}}{{h}_{i}} \right)$
(19) $\begin{matrix} {{L}_{\text{classification }}}= \\ -\frac{1}{2N}\sum\limits_{i=1}^{2N}{\sum\limits_{j=1}^{2}{1}}\left\{ {{y}_{i,j}}=1 \right\}\log \frac{\exp {{{\hat{y}}}_{i,j}}}{\sum\limits_{j=1}^{2}{\exp }\left( {{{\hat{y}}}_{i,j}} \right)} \\ \end{matrix}$
式中,${{y}_{i}}$ ${{\hat{y}}_{i}}$ ${{W}_{f1}}\in {{R}^{m\times d}}$ ${{W}_{f2}}\in {{R}^{d\times 2}}$ d 设为128。
步骤4:本文通过打乱一些数据的时间步长来生成数据集的假样本,随之通过辅助分类任务训练编码器,检测给定的时间序列是真实还是虚假。训练过程中进一步对编码器进行微调的过程。在图9 中本文冻结部分DTCR模块,使用Autonomous- cognition模块进行训练。
图9
图9
微调的Autonomous-cognition模块训练流程图
3.2 整体损失函数
最后本文通过上述步骤训练后再次对数据集进行验证时,对AC-DTCR的整体训练损失${{L}_{\mathrm{AC-DTCR}}}$
(20) ${{L}_{DTCR}}={{L}_{\text{reconstruction }}}+{{L}_{\text{classification}}}+\lambda {{L}_{K-\text{means }}}$
式中,$\lambda $ ${{L}_{\text{reconstruction }}}$ ${{L}_{\text{classification}}}$ ${{L}_{K-\text{means }}}$
4 算例分析
4.1 问题描述
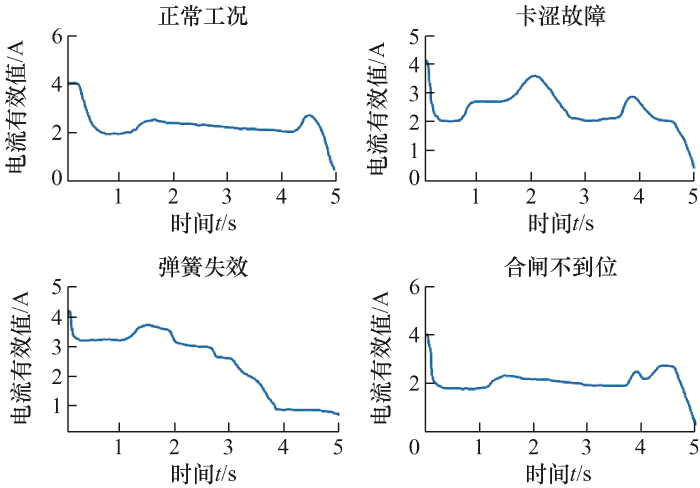
以高压隔离开关为对象进行模拟试验,模拟高压隔离开关正常工况、卡涩故障、弹簧失效、合闸不到位四种工况。试验得到高压隔离开关对应的四种故障测试的100组定子电流数据,其中70组数据设置为训练数据,10组数据用于测试,20组数据用于验证模型的准确率,不同工况对应电流归一化有效值如图10 所示。
图10
4.2 半监督训练
模型设置初始学习率为5×10-2 ,使用Adam优化器进行优化,迭代次数设置为50次。
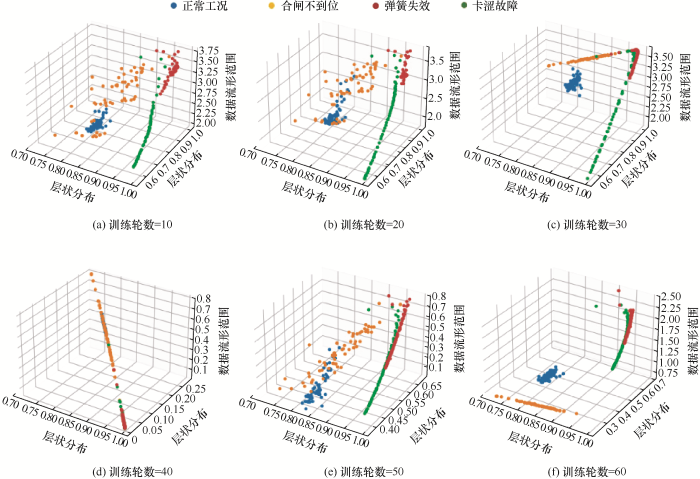
图11 为半监督训练数据三维流形图。随着训练轮数的增加,相同类型的数据慢慢地往一起聚合,不同类型的数据慢慢被分开。最后可以看出该模型的分类效果具有可行性。
图11
由于本文模型使用半监督训练,主要是利用自主认知分类器,因此为了证明本文模型能够借助类感知分类提高分类效果,通过以下试验进行验证。
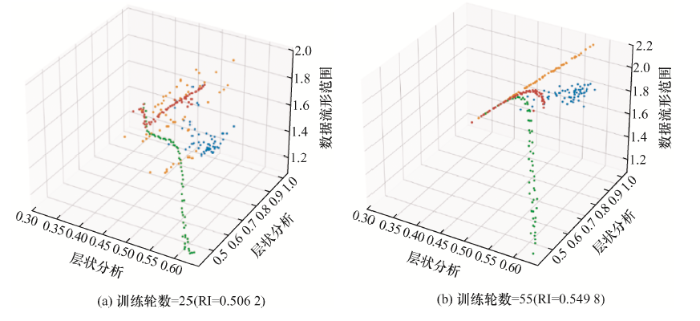
兰德指数(Rand index, RI)用于评估聚类性能,可以定义为
(21) $RI=\frac{TP+TN}{n(n-1)/2}$
式中,TP(True positive)是正确放入同一集群的时间序列对的数量,TN(True negative)是正确放入不同集群的时间序列对的数量,n 是数据集的大小。
从图12 可以看出,训练轮数达到25时的分类效果要比55轮的分类效果差,结合兰德指数,可以得出模型在训练后聚类效果越来越好,结合图像分析,模型的聚类效果良好。
图12
4.3 对比试验
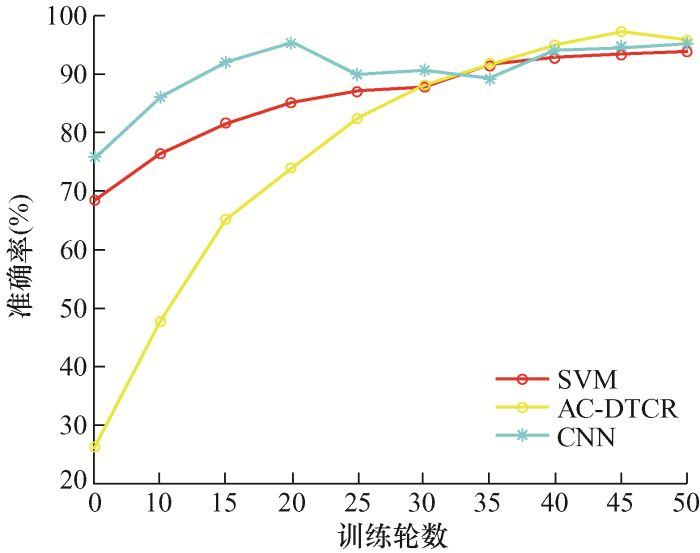
为验证方法的有效性,本文将与卷积神经网络(Convolutional neural network,CNN)和支持向量机(Support vector machine,SVM)进行对比试验,模型参数设置保持一致。为了减少随机性的影响,将每组试验重复10次,单个目标域的平均准确率曲线和总体准确率曲线如图13 所示,准确率定义为正确分类的测试样本占样本总数的百分比。
图13
由图13 可以发现,随着学习轮数和迭代次数的增加,AC-DTCR算法准确率在不断增高,但是在40轮往后,准确率增长缓慢,最终的故障识别率可以达到97%,在45轮往后,识别的准确率略有下降,可能的原因是模型过拟合或者学习率设置过大。SVM和CNN算法在训练的轮数较小时准确率高于AC-DTCR,但是在训练轮数越来越大时准确率不如AC-DTCR,且在训练结束,AC-DTCR在最终准确率上要比SVM和CNN高出1%~2%。
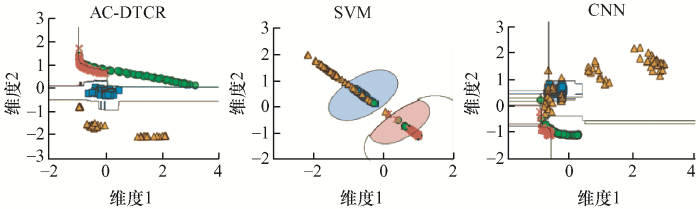
为验证本文所提方法的合理性,针对所提方法、SVM与CNN的最佳分类器的决策边界做了比较,由图14 可以明显看出,AC-DTCR可以将所有的时间序列明显区分开来。而SVM与CNN决策边界的区分度不够明显。总的来说,混乱的时间序列得到了很好的分离,这表明本文提出的聚类算法在分类任务中的效果明显。
图14
5 结论
为准确诊断隔离开关所发生的故障类型,本文提出了一种基于自主认知的深度时序聚类算法(Autonomous-cognition deep temporal clustering representation,AC-DTCR),将时间重构和K-means目标集成到seq2seq模型中,使学习到的表示能够编码时间序列并形成聚类结构,最终达到对隔离开关故障类型准确分类的目的,得到如下结论。
(1) 基于自主认知的深度时序聚类算法对隔离开关电机电流时序数据有着更好的处理,并提出了一种针对时间序列和辅助分类任务的假样本生成策略,提高了编码器的能力。
(2) 解决了数据量小且需要对样本进行标记的问题,使用将隔离开关的故障数据进行分类诊断,并与传统的SVM、CNN算法进行对比,结果表示AC-DTCR有更高的准确率。
参考文献
View Option
[1]
构建基于“大云物移智”等现代信息通信技术的智能运检体系
[J]. 电力设备管理 , 2019 ,4:26 -27 .
[本文引用: 1]
Construction of intelligent operation inspection system based on modern information and communication technologies such as “big cloud and object mobile intelligence”
[J]. Electric Power Equipment Management , 2019 ,4:26 -27 .
[本文引用: 1]
[2]
邱志斌 , 阮江军 , 黄道春 , 等 . 高压隔离开关机械故障分析及诊断技术综述
[J]. 高压电器 , 2015 , 51 (8 ):171 -179 .
[本文引用: 1]
QIU Zhibin RUAN Jiangjun HUANG Daochun et al. Review of mechanical fault analysis and diagnosis technology of high voltage disconnector
[J]. High Voltage Apparatus , 2015 , 51 (8 ):171 -179 .
[本文引用: 1]
[3]
KIM K PARLOS A G BHARADWAJ R M Sensorless fault diagnosis of induction motors
[J]. IEEE Transactions on Industrial Electronics , 2003 , 50 (5 ):1038 -1051 .
DOI:10.1109/TIE.2003.817693
URL
[本文引用: 1]
[4]
李少华 , 张文涛 , 宋亚凯 , 等 . 基于高压隔离开关振动信号的故障诊断方法分析
[J]. 内蒙古电力技术 , 2018 , 36 (1 ):89 -92 .
[本文引用: 1]
LI Shaohua ZHANG Wentao SONG Yakai et al. Analysis of fault diagnosis method based on vibration signal of high voltage disconnector
[J]. Inner Mongolia Electric Power Technology , 2018 , 36 (1 ):89 -92 .
[本文引用: 1]
[5]
ZHAO Lihua HONG Guo WANG Zelong et al. Research on fault vibration signal features of GIS disconnector based on EEMD and kurtosis criterion
[J]. IEEJ Transactions on Electrical and Electronic Engineering , 2021 , 16 (5 ):677 -686 .
DOI:10.1002/tee.v16.5
URL
[本文引用: 1]
[6]
王黎明 , 何建明 . 电动隔离开关机械故障状态监测的设想
[J]. 浙江电力 , 2006 ,3:56 -59 .
[本文引用: 1]
WANG Liming HE Jianming Assumption of mechanical fault condition monitoring of electric disconnector
[J]. Zhejiang Electric Power , 2006 ,3:56 -59 .
[本文引用: 1]
[7]
FUJITA A SEVERINO P KOJIMA K et al. Functional clustering of time series gene expression data by Granger causality
[J]. BMC Systems Biology , 2012 ,6:1 -12 .
[本文引用: 1]
[8]
CHAN P K MAHONEY M V Modeling multiple time series for anomaly detection
[C]// Fifth IEEE International Conference on Data Mining (ICDM’05 ). IEEE,2005:8.
[本文引用: 1]
[9]
AGHABOZORGI S SHIRKHORSHIDI A S WAH T Y Time-series clustering:A decade review
[J]. Information Systems , 2015 ,53:16 -38 .
[本文引用: 1]
[10]
孙志鹏 , 孙志龙 , 魏建 . 基于决策树支持向量机算法的电力变压器故障诊断研究
[J]. 电气工程学报 , 2019 , 14 (4 ):42 -45 .
[本文引用: 1]
SUN Zhipeng SUN Zhilong WEI Jian Research on fault diagnosis of power transformer based on decision tree support vector machine algorithm
[J]. Journal of Electrical Engineering , 2019 , 14 (4 ):42 -45 .
[本文引用: 1]
[11]
于聪 , 汤凯波 , 李哲 , 等 . 基于BP神经网络与改进DS证据融合的GIS设备局放故障识别
[J/OL]. 电气工程学报 :1 -9 [2023-10-21]. http://kns.cnki.net/kcms/detail/10.1289.TM.20230725.1006.006.html.
URL
[本文引用: 2]
YU Cong TANG Kaibo LI Zhe et al. PDS fault identification of GIS equipment based on BP neural network and improved DS evidence fusion
[J/OL]. Journal of Electrical Engineering :1 -9 [2023-10-21]. http://kns.cnki.net/kcms/detail/10.1289.TM.20230725.1006.006.html.
URL
[本文引用: 2]
[12]
LEI Huang XIA Yingcun QIN Xu Estimation of semivarying coefficient time series models with ARMA errors
[J]. The Annals of Statistics , 2016 , 44 (4 ):1618 -1660 .
[本文引用: 2]
[13]
CAI Zongwu FAN Jianqing YAO Qiwei Functional-coefficient regression models for nonlinear time series
[J]. Journal of the American Statistical Association , 2000 , 95 (451 ):941 -956 .
DOI:10.1080/01621459.2000.10474284
URL
[本文引用: 1]
[14]
YANG Yi SHEN Hengtao Ma Zhigang et al. ℓ 2, 1-norm regularized discriminative feature selection for unsupervised learning
[C]// IJCAI International Joint Conference on Artificial Intelligence . 2011 .
[本文引用: 1]
[15]
LI Zechao YANG Yi LIU Jing et al. Unsupervised feature selection using nonnegative spectral analysis
[C]// Proceedings of the AAAI Conference on Artificial Intelligence , 2012 , 26 (1 ):1026 -1032 .
[本文引用: 1]
[16]
钱明杰 , 翟承祥 . 鲁棒性的无监督特征选择
[C]// 人工智能国际联合会议 , 2013 .
[本文引用: 1]
QIAN Mingjie ZHAI Chengxiang Robust unsupervised feature selection
[C]// International Joint Conference on Artificial Intelligence , 2013 .
[本文引用: 1]
[17]
SHI Lei DU Liang SHEN Yidong Robust spectral learning for unsupervised feature selection
[C]// In 2014 IEEE International Conference on Data Mining,IEEE,2014: 977 -982 .
[本文引用: 1]
[18]
DU Xinlong HAJJAR J F BOND R B et al. Clustering and selection of hurricane wind records using autoencoder and K-means algorithm
[J]. Journal of Structural Engineering , 2023 , 149 (8 ):4023096 .
DOI:10.1061/JSENDH.STENG-12110
URL
[本文引用: 1]
[19]
TJOSTHEIM D AUESTAD B H Nonparametric identification of nonlinear time series:Projections
[J]. Journal of the American Statistical Association , 1994 , 89 (428 ):1398 -1409 .
[本文引用: 1]
[20]
MA Qianli LI Sen SHEN Lifeng et al. End-to-end incomplete time-series modeling from linear memory of latent variables
[J]. IEEE Transactions on Cybernetics , 2019 , 50 (12 ):4908 -4920 .
DOI:10.1109/TCYB.6221036
URL
[本文引用: 1]
构建基于“大云物移智”等现代信息通信技术的智能运检体系
1
2019
... 为了保证电网可靠性供电的目标,实现“零停电、零投诉”,电网需要通过“智能装备、智慧运行”的发展路径充分探索智能化手段在设备运维和故障诊断方面的可行策略,在运维人员定额不变的现有条件下全面提升变电设备管控能力[1 ] . ...
Construction of intelligent operation inspection system based on modern information and communication technologies such as “big cloud and object mobile intelligence”
1
2019
... 为了保证电网可靠性供电的目标,实现“零停电、零投诉”,电网需要通过“智能装备、智慧运行”的发展路径充分探索智能化手段在设备运维和故障诊断方面的可行策略,在运维人员定额不变的现有条件下全面提升变电设备管控能力[1 ] . ...
高压隔离开关机械故障分析及诊断技术综述
1
2015
... 在电力系统的运行中,高压隔离开关是使用场合极多的一次设备.其原理结构相对简单,但是绝大多数是在户外使用,在面临不同恶劣环境时,例如大雨、大雪、暴晒时可能会导致其出现各种不同的故障,这将会对电力系统的稳定运行造成影响.在隔离开关的缺陷大类中,主要分为操作机构轻微卡涩、操作机构严重卡涩、平衡弹簧失效、动触头合闸不到位[2 ] 等.随着新投入运变电站数量的与日俱增,隔离开关故障导致的电网非计划停运事故事件占比越来越高,直接影响到电厂的功率出力以及用户供电情况,严重影响了电网供电的可靠性及稳定性,对社会经济发展产生不良影响.文献[3 ]通过监测电机电流来获取电机机械状态特征量,同时研究特征量提取方法,建立机械故障诊断系统. ...
Review of mechanical fault analysis and diagnosis technology of high voltage disconnector
1
2015
... 在电力系统的运行中,高压隔离开关是使用场合极多的一次设备.其原理结构相对简单,但是绝大多数是在户外使用,在面临不同恶劣环境时,例如大雨、大雪、暴晒时可能会导致其出现各种不同的故障,这将会对电力系统的稳定运行造成影响.在隔离开关的缺陷大类中,主要分为操作机构轻微卡涩、操作机构严重卡涩、平衡弹簧失效、动触头合闸不到位[2 ] 等.随着新投入运变电站数量的与日俱增,隔离开关故障导致的电网非计划停运事故事件占比越来越高,直接影响到电厂的功率出力以及用户供电情况,严重影响了电网供电的可靠性及稳定性,对社会经济发展产生不良影响.文献[3 ]通过监测电机电流来获取电机机械状态特征量,同时研究特征量提取方法,建立机械故障诊断系统. ...
Sensorless fault diagnosis of induction motors
1
2003
... 在电力系统的运行中,高压隔离开关是使用场合极多的一次设备.其原理结构相对简单,但是绝大多数是在户外使用,在面临不同恶劣环境时,例如大雨、大雪、暴晒时可能会导致其出现各种不同的故障,这将会对电力系统的稳定运行造成影响.在隔离开关的缺陷大类中,主要分为操作机构轻微卡涩、操作机构严重卡涩、平衡弹簧失效、动触头合闸不到位[2 ] 等.随着新投入运变电站数量的与日俱增,隔离开关故障导致的电网非计划停运事故事件占比越来越高,直接影响到电厂的功率出力以及用户供电情况,严重影响了电网供电的可靠性及稳定性,对社会经济发展产生不良影响.文献[3 ]通过监测电机电流来获取电机机械状态特征量,同时研究特征量提取方法,建立机械故障诊断系统. ...
基于高压隔离开关振动信号的故障诊断方法分析
1
2018
... 文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路.文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征.文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性. ...
Analysis of fault diagnosis method based on vibration signal of high voltage disconnector
1
2018
... 文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路.文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征.文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性. ...
Research on fault vibration signal features of GIS disconnector based on EEMD and kurtosis criterion
1
2021
... 文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路.文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征.文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性. ...
电动隔离开关机械故障状态监测的设想
1
2006
... 文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路.文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征.文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性. ...
Assumption of mechanical fault condition monitoring of electric disconnector
1
2006
... 文献[4 ]为高压隔离开关的机械故障的检测提供了新的思路,通过检测高压隔离开关的振动信号,来对机械故障进行定性分析,结合聚类算法的应用,为高压隔离开关的检测拓宽了思路.文献[5 ]搭建了GIS隔离开关接触故障仿真平台,采集隔离开关100种状态的振动信号,通过重构筛选信号得到不同工况下GIS的振动信号特征.文献[6 ]利用隔离开关电机的电流和机械转角这两个特征量监测机械结构的运行状态,但暂未通过试验验证方案的可行性. ...
Functional clustering of time series gene expression data by Granger causality
1
2012
... 时间序列聚类算法是一种重要的数据挖掘技术,被广泛应用于基因组数据[7 ] 、异常检测[8 ] 以及任何需要模式监测的领域.时间序列聚类有助于发现有用的模式,使数据分析人员能从复杂和大规模的数据中提取有价值的信息[9 ] . ...
Modeling multiple time series for anomaly detection
1
... 时间序列聚类算法是一种重要的数据挖掘技术,被广泛应用于基因组数据[7 ] 、异常检测[8 ] 以及任何需要模式监测的领域.时间序列聚类有助于发现有用的模式,使数据分析人员能从复杂和大规模的数据中提取有价值的信息[9 ] . ...
Time-series clustering:A decade review
1
2015
... 时间序列聚类算法是一种重要的数据挖掘技术,被广泛应用于基因组数据[7 ] 、异常检测[8 ] 以及任何需要模式监测的领域.时间序列聚类有助于发现有用的模式,使数据分析人员能从复杂和大规模的数据中提取有价值的信息[9 ] . ...
基于决策树支持向量机算法的电力变压器故障诊断研究
1
2019
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Research on fault diagnosis of power transformer based on decision tree support vector machine algorithm
1
2019
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
基于BP神经网络与改进DS证据融合的GIS设备局放故障识别
2
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
... [11 -12 ].然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
PDS fault identification of GIS equipment based on BP neural network and improved DS evidence fusion
2
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
... [11 -12 ].然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Estimation of semivarying coefficient time series models with ARMA errors
2
2016
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
... -12 ].然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Functional-coefficient regression models for nonlinear time series
1
2000
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
? 2, 1-norm regularized discriminative feature selection for unsupervised learning
1
2011
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Unsupervised feature selection using nonnegative spectral analysis
1
2012
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
鲁棒性的无监督特征选择
1
2013
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Robust unsupervised feature selection
1
2013
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Robust spectral learning for unsupervised feature selection
1
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Clustering and selection of hurricane wind records using autoencoder and K-means algorithm
1
2023
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
Nonparametric identification of nonlinear time series:Projections
1
1994
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...
End-to-end incomplete time-series modeling from linear memory of latent variables
1
2019
... 基于特征的方法[10 -11 ] 通常由提取的特征和聚类组成.该方法对噪声具有鲁棒性,可以滤除一些不相关的信息[12 ] ,从而降低数据维度,提高聚类算法的效率[11 -12 ] .然而,现有方法大多是领域相关的,需要领域知识来人工构建高质量的特征[13 ] .在许多研究中[14 ⇓ ⇓ -17 ] ,利用局部学习学习到的伪聚类标签,选择判别特征.然而,所选择的特征通常是线性的,而非线性动态特征在时间序列中更常见[18 ⇓ -20 ] . ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}