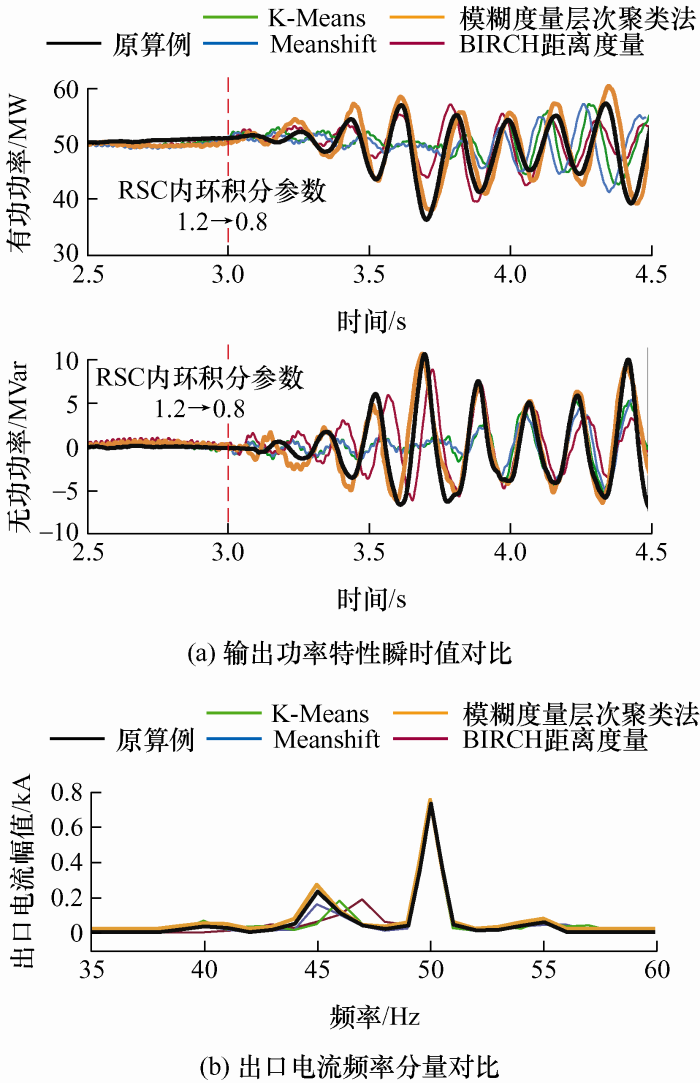
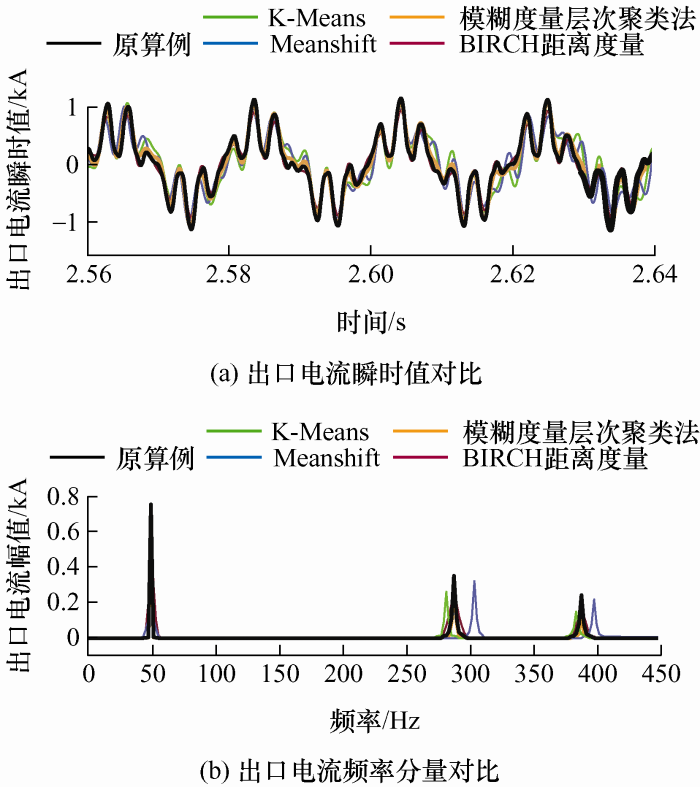
On account of the pressing goal of “carbon peaking and carbon neutrality”, it is extremely urgent to develop wind power and study the broadband oscillation problem of wind farm connected to the grid. With the purpose of establishing a simulation model suitable for wind farm oscillation research, which is able to accurately and efficiently reflect the actual wind farm output characteristics, a fuzzy hierarchical clustering method is proposed that improves the clustering result offset caused by distance measurement in traditional balanced iterative reducing and clustering using hierarchies. Besides, F test is used to evaluate the clustering effect quantitatively, and F score can be used to horizontally compare to determine the optimal cluster number and longitudinal comparison to determine the optimal clustering scheme. Compared with traditional clustering method, fuzzy metric hierarchical clustering method has the highest F score. Finally, a wind farm simulation example consisting of 25 wind turbines with actual parameters in PSCAD is set up, and the conclusion is obtained that the most suitable clustering method for wind farms is fuzzy metric hierarchical clustering method.
SONG Rui, GAN Jiatian, WANG Zejia, XU Decao, BAI Zuoxia, HAN Minxiao. Fuzzy Metric Hierarchical Clustering Method for Wind Farm Wideband Oscillation Research[J]. Chinese Journal of Electrical Engineering, 2024, 19(1): 261-271 doi:10.11985/2024.01.028
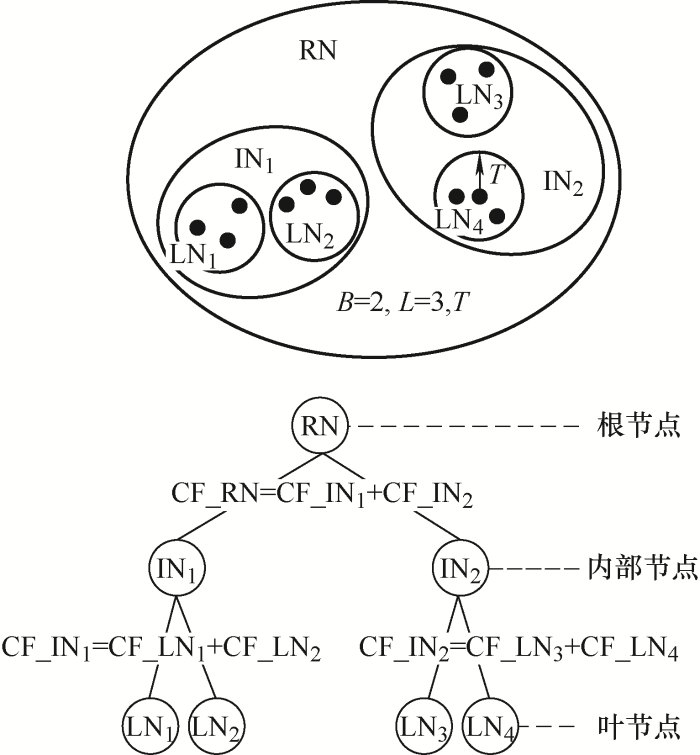
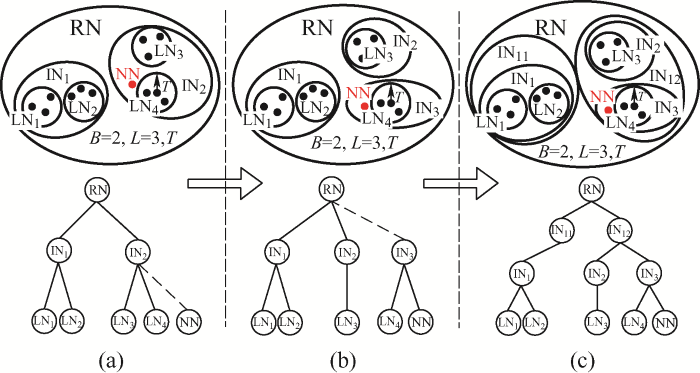
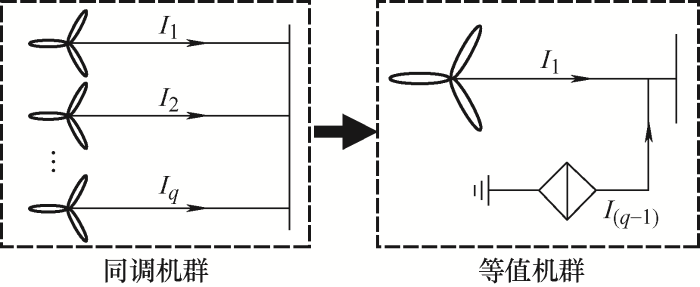
近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7]。目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用。为降低系统维度,提高运算速度,需要对风电场进行合理地等值。常用的方法包括单机等值和分群聚类。文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性。同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响。聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中。现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等。K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解。Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢。
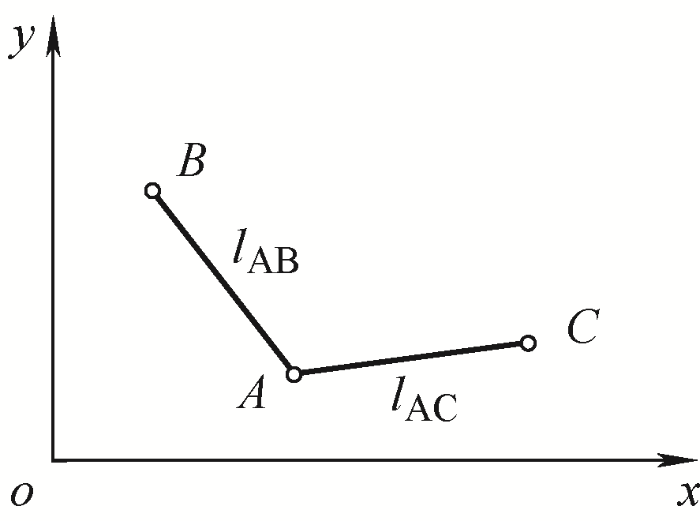
式中,k表示第k个分组;h表示第h个特征;${{\overline{b}}_{k}}$为k分组内的样本均值;$\overline{\overline{b}}$为全体样本均值;分子SSB(Sum of square between group)表示组间偏差平方和;分母dfB为组间偏差平方和的自由度。已知全体样本均值和l-1个分组的样本均值,则可以得出最后一个分组的均值,因此组间偏差平方和的自由度为l-1。
Modeling and mechanism analysis of sub- and super-synchronous oscillation of grid-connected dfig wind farms:Analysis of impedance characteristic and oscillation mechanism
[J]. Proceedings of the CSEE, 2022, 42(10):3614-3626.
YUYiming.Middle and high frequency resonance analysis model and suppression strategy of wind farm[D]. Beijing: North China Electric Power University, 2020.
GAOJin.Transient voltage stability analysis of wind power grid connected based on Dpeak equivalent modeling[D]. Lanzhou: Lanzhou University of Technology, 2021.
Cluster analysis is used in many disciplines to group objects according to a defined measure of distance. Numerous algorithms exist, some based on the analysis of the local density of data points, and others on predefined probability distributions. Rodriguez and Laio devised a method in which the cluster centers are recognized as local density maxima that are far away from any points of higher density. The algorithm depends only on the relative densities rather than their absolute values. The authors tested the method on a series of data sets, and its performance compared favorably to that of established techniques.
Modeling and mechanism analysis of sub- and super-synchronous oscillation of grid-connected dfig wind farms:Analysis of impedance characteristic and oscillation mechanism
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Dynamic equivalent model of a grid-connected wind farm for oscillation stability analysis
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
电力电子设备高占比电力系统电磁振荡分析与抑制综述
1
2020
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Overview of the analysis and mitigation methods of electromagnetic oscillations in power systems with high proportion of power electronic equipment
1
2020
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
考虑换流器外环特性的双馈风电场并网稳定性分析
3
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
General impedance model with out-loop for DFIG wind farm stability analysis
3
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Research on density peak clustering method for wind speed prediction of wind farm
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
基于改进K-means聚类算法的风电场动态等值
1
2018
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Dynamic equivalence of wind farm based on improved K-means clustering algorithm
1
2018
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
1
2020
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
1
2020
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
基于聚类分析的双馈机组风电场动态等值模型的研究
1
2013
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Study on dynamic equivalence of wind farms with DFIG based on clustering analysis
1
2013
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
基于新型多维功率趋势聚类的风电功率预测方法
1
2022
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Wind power prediction method based on novel multi-dimensional power trend clustering
1
2022
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
大规模风电汇集系统小干扰稳定性研究综述
1
2022
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Research on small signal stability analysis of large-scale wind power collection system:An overview
1
2022
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
适应宽频振荡的风电并网系统主动阻尼技术综述
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Overview on active damping technology of wind power integrated system adapting to broadband oscillation
1
2021
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
新能源并网系统引发的复杂振荡问题及其对策研究
1
2017
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Study of complex oscillation caused by renewable energy integration and its solution
1
2017
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
A new hybrid model optimized by an intelligent optimization algorithm for wind speed forecasting
1
2014
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Short-term wind speed forecasting based on spectral clustering and optimised echo state networks
1
2015
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Dynamic equivalent modeling for wind farms with DFIGs using the artificial bee colony with K-Means algorithm
1
2020
... 近年来,众多学者从振荡触发机理、风电场等值方法、振荡影响因素和抑制策略等角度开展了广泛研究[4⇓⇓-7].目前主流的分析方式有阻抗分析法、特征值分析法、复转矩系数法等,这些方法揭示了宽频振荡现象的产生原理,但在仿真验证阶段又很难找到准确且高效的仿真模型,用来分析区域电网中多个风电场间及场站内部大量风电机组间的交互作用.为降低系统维度,提高运算速度,需要对风电场进行合理地等值.常用的方法包括单机等值和分群聚类.文献[8]阐述了风电场单机等值的理论基础,提供了一种模型简化方法,但是该方法要求忽略集电网络的影响,存在一定局限性.同时,单机等值方法会改变单个风电机组的特性,对分析风机控制参数的研究造成不利影响.聚类策略方面,目前风电场聚类的应用场景主要集中在风功率预测[9⇓⇓-12]和暂态稳定性分析[13-14]方面,较少应用在宽频振荡研究中.现有的聚类方法主要包括以K均值聚类算法(K-means clustering algorithm,K-Means)为代表的划分法[15-16]、以基于密度聚类算法(Density-based spatial clustering of applications with noise,DBSCAN)与均值漂移算法(Mean shift)为代表的密度法[17-18]、以综合层次聚类算法(Balanced iterative reducing and clustering using hierarchies,BRICH)为代表的层次聚类法[19]等.K-Means聚类法需要选取初始簇中心,会影响到迭代算法的收敛速度与聚类效果,在大型风电场的宽频振荡分析中初始中心的选择是较为盲目的,容易陷入局部最优解.Mean shift利用样本密度进行聚类,无需知道簇的数量,受均值影响小,但该算法需要在多个邻近区域搜索密度更高的区域,计算量较大,效率较慢. ...
Clustering by fast search and find of density peaks


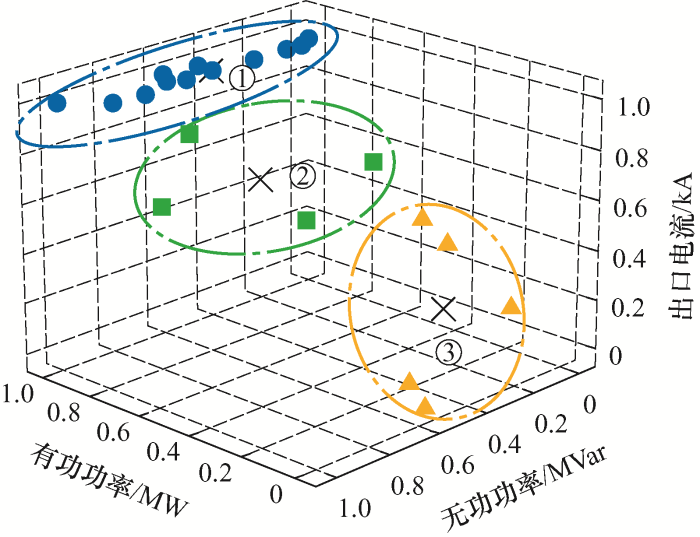
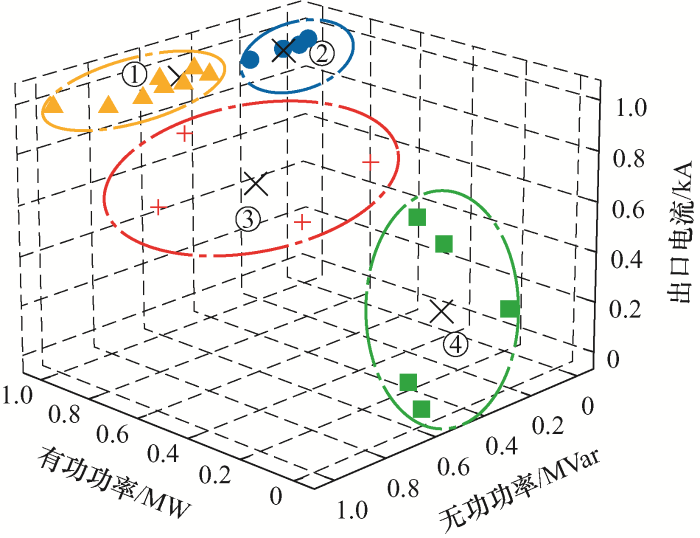
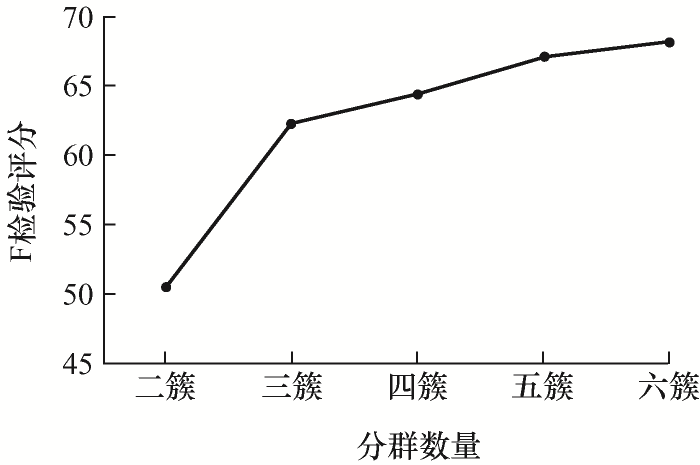
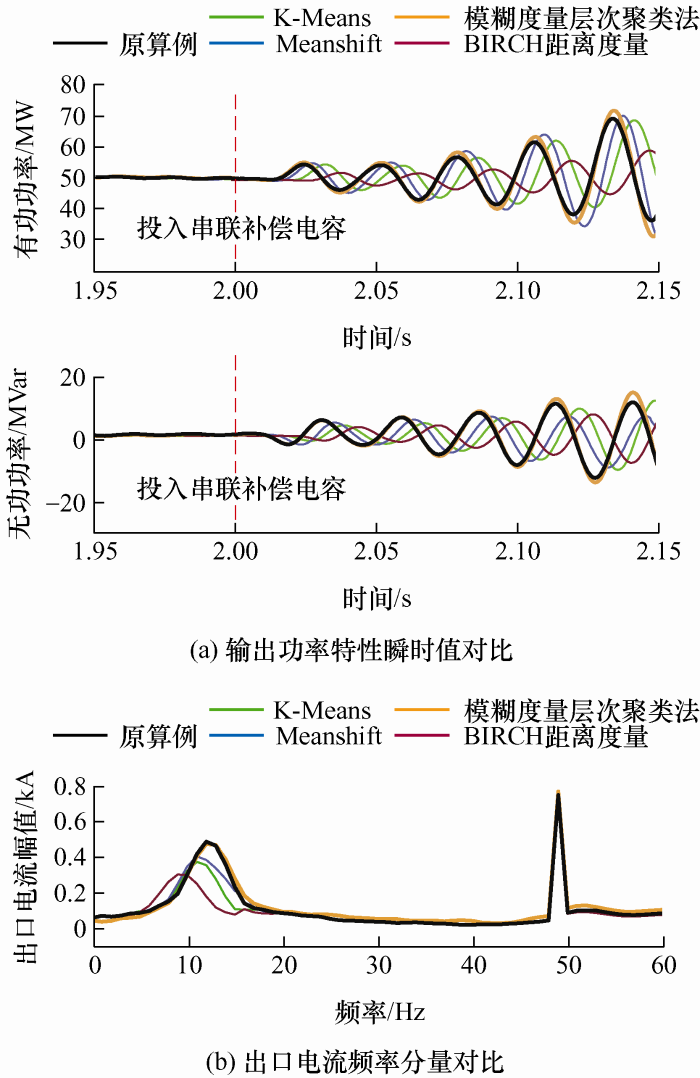


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}