1 引言
母线负荷预测是电力系统运营和规划中至关重要的一项任务。随着社会经济的不断发展和电力需求的不断增长,电力系统必须以高度可靠和高效的方式满足不断变化的负荷需求,准确有效的负荷预测可以为电力系统的可靠性与稳定性提供数据支撑。
随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] 。传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等。这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况。文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型。文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架。文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果。文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度。传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差。
随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据。基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等。文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升。文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升。文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型。文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法。文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法。
通过以上研究可以发现,负荷预测对获取负荷数据的趋势和降噪的问题越来越重视,同时对可能影响负荷的因素更加关注。本文根据这一特点提出了一种基于双模态分解、深度学习和注意力机制的EMD-SSA-VMD-LSTM-Attention母线负荷预测模型。首先,对负荷数据进行预处理,将数据通过经验模态分解(Empirical mode decomposition, EMD)分解成多个模态,使用样本熵对每个模态的复杂度进行计算,根据样本熵的大小分将多模态分为高中低三个类别,通过K-means聚类分析将不同类别的分量进行集合得到三个组合分量。其次,使用变分模态分解(Variational mode decomposition, VMD)对组合分量进行二次分解,为了避免VMD参数设置的盲目性,使用麻雀搜索算法(Sparrow search algorithm, SSA)对VMD进行优化。最后,将采集到的负荷影响因素如温度、湿度、风力等数据和VMD分解得到的模态分量输入到长短期记忆网络(Long short-term memory network, LSTM)中,并通过注意力机制(Attention)挖掘数据内部的相关性,最终通过数据重构得到负荷结果并对结果进行分析。通过对比EMD-SSA-VMD-LSTM-Attention模型与相同输入数据的LSTM、EMD-LSTM、EMD-LSTM- Attention模型的运行结果,可以看出新模型的预测准确度有所提升。
2 理论基础
电力系统负荷数据的非线性强、环境和社会影响因素多的特点对负荷预测的准确性提出了较大的挑战。为了解决这些问题,本文将经验模态分解、麻雀搜索算法、变分模态分解运用到负荷预测模型中,对历史负荷数据进行两次模态分解,用以更好地捕捉负荷数据的潜在模态和趋势,降低噪声和干扰的影响。为了更好地捕捉时间序列数据中的长期依赖关系,增加模型动态适应性,在模型中加入长短期记忆网络。同时为了捕捉环境和社会影响因素与负荷数据的相关性,在模型中加入注意力机制,用以提高负荷预测的准确性。
2.1 经验模态分解
经验模态分解法(EMD)分解是一种处理非线性、非平稳信号的自适应分解方法[21 ] 。它会根据时间序列数据的特性自动生成本征模态函数(IMF),直到数据被分解为不再包含明显的振荡或模式为止。每个IMF表征信号的局部特征,反映负荷数据的波动性、周期性和趋势变化。对负荷数据进行预处理后将其转换为一组一维时间序列数据x (t )并进行EMD分解,将分解得到不同的模态经处理后作为二次分解的输入数据,EMD具体分解步骤如下所示。
步骤1:局部极值点提取。找到x (t )中的所有局部极值点,包括极大值和极小值。这些极值点将用于确定IMF的包络线。
步骤2:包络线提取。通过插值或拟合方法,得到信号x (t )的上包络线(记为u (t ))和下包络线(记为l (t )),这些包络线连接了局部极值点。
步骤3:IMF提取。依次执行以下步骤,直到满足停止条件:① 计算平均值: $h(t)=\frac{u(t)+I(t)}{2}$ x (t )与平均值m (t )相减得到一个新信号${{c}_{1}}(t)=r(t)-h(t)$ c 1 (t )是否为IMF:当c 1 (t )极值点的数量为零,或极大值点和极小值点之间的数量差不超过1以及在整个信号中,c 1 (t )的均值为零或接近于零时,c 1 (t )满足成为IMF的定义条件。如果c 1 (t )满足条件,则c 1 (t )被认为是第一个IMF(IMF1),将x (t )与IMF1相减得到一个新信号${{r}_{1}}(t)=x(t)-\mathrm{IMF}1$ r 1 (t )作为原始信号重新代入分解,否则将c 1 (t )作为新的 x (t )进行迭代。多次分解直到残余分量rn (t )是单调函数或常量时,EMD分解过程停止。
(1) $x(t)=\sum\limits_{i=1}^{n}{{{c}_{i}}}(t)+{{r}_{n}}(t)$
2.2 变分模态分解
变分模态分解(VMD)利用求解变分问题的思想去对信号进行提取,在不丢失原始信号特征的情况下,把一个原始信号分解成多个不同中心频率的信号,适用于非线性时间序列信号。VMD分解是一种完全非递归的迭代优化方法,需要通过不断迭代优化模态函数来逼近原始信号。通过麻雀搜索算法对VMD分解的模态数、正则化参数及迭代次数等参数进行优化以获取最小化信号重构误差和正则化项,得到最佳的模态函数。样本熵是一种度量时间序列复杂度的方法[22 ] 。将EMD分解得到的多个模态通过样本熵计算分量复杂度,然后通过K-means算法将其重组得到三个分量,将三个分量作为VMD分解的输入数据。假设输入信号f (t )能够分解为K 个有限带宽的模态分量,所有模态之和等于原始信号,各模态的估计带宽之和最小,VMD分解的约束变分模型如下
(2) $\left\{ \begin{align} & \underset{\{{{u}_{k}},{{w}_{k}}\}}{\mathop{\min }}\,\left\{ \sum\limits_{k}{\left\| {{\partial }_{t}}\left[ \left( \sigma (t)+\frac{j}{\mathrm{ }\!\!\pi\!\!\text{ }t} \right)\cdot {{u}_{k}}(t) \right]\exp (-\mathrm{j}{{w}_{k}}t) \right\|_{2}^{2}} \right\} \\ & \mathrm{s}.\mathrm{t}.\ \ \ \sum\limits_{k}{{{u}_{k}}}=f \\ \end{align} \right.$
式中,f (t )为输入信号;uk 为分解后的模态分量;wk 为模态分量的中心频率;uk (t )为第k 个模态分量在t 时刻的值。
为了找到约束变分问题的最优解,通过拉格朗日乘子τ (t )和二阶惩罚因子α ,将约束变分问题转化为无约束变分问题,公式如下
(3) $L(\{{{v}_{k}}\},\{{{w}_{k}}\},\tau )=a{{\sum\limits_{k}{\left\| {{\partial }_{t}}\left[ \left( \delta (t)+\frac{j}{\mathrm{ }\!\!\pi\!\!\text{ }t} \right)\cdot {{v}_{k}}(t) \right]\exp {{(-\mathrm{j}\mathop{w}_{k}t)}^{{}}} \right\|}}^{2}}+{{\left\| s(t)-\sum\limits_{k}{{{v}_{k}}(t)} \right\|}^{2}}+\left\langle \tau (t),s(t)-\sum\limits_{k}{{{v}_{k}}(t)} \right\rangle $
式中,$\delta (t)$ α 可以保证高斯噪声环境下信号重构的准确性;拉格朗日乘子τ (t )可以保证保持约束条件的严格性。
(3) 利用交替方向乘子法和傅里叶等距变换,迭代模态分量vk 、中心频率wk 和拉格朗日乘子τ (t ),当满足$\sum\limits_{k}{\left( \left\| \hat{V}_{k}^{n+1}-\hat{V}_{k}^{n} \right\|_{2}^{2}/\left\| \hat{V}_{k}^{n} \right\|_{2}^{2} \right)}<\varepsilon $ ε >0。
2.3 长短期记忆网络
LSTM是一种改进的循环神经网络(Recurrent neural network, RNN),目的是解决传统RNN中的长期依赖问题。它继承了大部分RNN模型的特性,同时有效地解决了梯度反向传播过程中的梯度问题。LSTM在负荷预测中在处理时序数据、捕捉长期依赖、适应不同尺度以及处理非线性关系等方面有很好的效果。合适的数据预处理和网络参数对预测准确性有较大影响,将VMD二次分解得到的模态分量及负荷影响因素如温度、湿度、风力等信息作为输入数据,同时拟采用麻雀搜索算法对LSTM网络中隐藏层神经元个数、丢弃率及批次大小等参数进行优化,以更好地发挥LSTM网络的性能,提高其准确性和泛化能力。
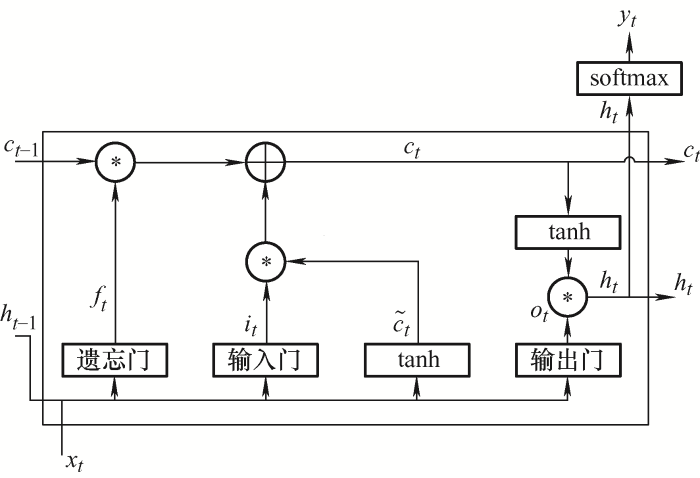
LSTM单元的内部结构如图1 所示。每个LSTM单元有3个门结构:遗忘门、输入门和输出门[18 ] 。xt 为t 时刻的输入向量,ct -1 为t -1时刻的记忆单元状态、ht -1 为t -1时刻的隐含层状态,ct -1 和ht -1 为LSTM单元模块t 时刻的输入量。LSTM单元内部信息运行如下所示。
图1
(1) 遗忘门控制细胞状态中信息的保留和遗忘。遗忘门读取上一个输出的隐含层状态ht -1 和当前输入xt ,通过Sigmoid函数进行非线性映射得到向量ft ,ft 各维度的值在0到1之间,1表示信息保留,0表示信息舍弃,ft 通过与细胞状态Ct -1 相乘来控制细胞状态中哪些信息应该被遗忘。
(4) ${{f}_{t}}=\sigma ({{W}_{fh}}{{h}_{t-1}}+{{W}_{fx}}{{x}_{t}}+{{b}_{f}})$
式中,ft 为遗忘门的信息,W fh W fx ht -1 、xt 的连接权值矩阵;b f σ 为Sigmoid函数。
(2) 输入门控制细胞状态中存放的新信息。输入门的Sigmoid激活函数决定被存放在细胞状态中的新信息,tanh层创建一个新的候选值向量${{\tilde{C}}_{t}}$
(5) $\left\{ \begin{align} & {{i}_{t}}=\sigma ({{w}_{ih}}{{h}_{t-1}}+{{w}_{ix}}{{x}_{t}}+{{b}_{i}}) \\ & {{{\tilde{C}}}_{t}}=\tanh ({{w}_{ch}}{{h}_{t-1}}+{{w}_{cx}}{{x}_{t}}+{{b}_{c}}) \\ \end{align} \right.$
式中,it 为输入门的信息;w ih w ix ht - 1 、xt 的连接权值矩阵;b i ${{\tilde{C}}_{t}}$ t 时刻输入记忆单元模块的信息;b c 为预备信息偏置向量;w ch w cx ht - 1 、xt 与${{\tilde{C}}_{t}}$
(3) 细胞状态更新通过${{C}_{t}}={{f}_{t}}\cdot {{C}_{t-1}}+{{i}_{t}}\cdot {{\tilde{C}}_{t}}$ Ct 是新的细胞状态;ft 是遗忘门的输出,用于确定要从旧细胞状态Ct - 1 中丢弃的信息;it 是输入门的输出,用于确定候选值${{\tilde{C}}_{t}}$
(4) 输出门控制细胞状态中的输出信息。输出门通过Sigmoid激活函数计算开启程度ot ,ot 决定是否输出ht 中的信息。实现公式为
(6) $\left\{ \begin{align} & {{o}_{t}}=\sigma ({{w}_{oh}}{{h}_{t-1}}+{{w}_{ox}}{{x}_{t}}+{{b}_{o}}) \\ & {{h}_{t}}={{o}_{t}}\cdot \tanh ({{c}_{t}}) \\ \end{align} \right.$
式中,ot 为输出门的信息;w oh w ox ht -1 、xt 的连接权值矩阵;b o
2.4 麻雀搜索算法
麻雀搜索算法(SSA)是一种基于麻雀觅食行为与反捕食行为的智能优化算法[23 ] 。作为一种新兴的启发式优化方法,该算法受到麻雀群体行为的启发,在很多领域中展现出了潜力。通过模拟麻雀集体智慧,麻雀搜索算法为解决复杂的优化问题提供了一种新的视角和有效的求解策略。麻雀搜索算法将麻雀群分为发现者、跟随者和警戒者三种类型,其中找到较好食物的个体作为发现者,发现者觅食并为种群提供觅食信息;跟随者通过发现者发出的信息进行觅食和位置更新;种群中意识到危险的麻雀作为警戒者,遇到危险时发出信息防备天敌。通过麻雀搜索算法可以对VMD和LSTM网络中的参数进行优化,SSA步骤如下所示。
步骤1:种群初始化。包括创建初始个体解、确保个体的唯一性、设置相关算法参数以及计算每个个体的适应度值。
步骤2:更新发现者位置。麻雀中找到食物较好的个体作为发现者,发现者觅食并为种群提供觅食区域和方向,发现者有更大的觅食搜索范围,其位置公式为
(7) $X_{i,j}^{t+1}=\left\{ \begin{align} & X_{i,j}^{t}\cdot \exp (\frac{-i}{a\cdot \mathrm{ite}{{\mathrm{r}}_{\max }}}){{R}_{2}}<\mathrm{ST} \\ & X_{i,j}^{t}+Q\cdot L\ \ \ \ \ \ \ \ \ \ \ \ {{R}_{2}}\ge \mathrm{ST} \\ \end{align} \right.$
式中,i 为发现者;$x_{i,j}^{t}$ i 只麻雀在第t 次迭代时的位置的j 维坐标;a 为[0,1 ]的随机数;R 2 为[0,1 ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值。当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数。
步骤3:种群中的跟随者会根据发现者的能量高低(即适应度值的优劣)确定寻觅的位置,追随者位置的更新公式为
(8) $X_{i, j}^{t+1}=\left\{\begin{array}{ll}X_{\text {best }}^{t}+\beta \cdot\left|X_{i, j}^{t}-X_{\text {best }}^{t}\right| & f_{i}>f_{g} \\X_{i, j}^{t}+K \cdot \frac{\left|X_{i, j}^{t}-X_{\text {worst }}^{t}\right|}{\left(f_{i}-f_{w}\right)+\varepsilon} & f_{i}=f_{g}\end{array}\right.$
式中,n 为加入者数量;$x_{\mathrm{worst}}^{t}$ t 次迭代中最差的个体;Xp 为目前最优发现者的位置;A d 的矩阵,元素为随机赋值的1或-1。当该加入者为前一半的较优加入者时,用第一个子公式更新位置,当该加入者为后一半的较差加入者时,相当于麻雀非常饥饿,需要随机飞到别的地方。
步骤4:种群中意识到危险的麻雀作为警戒者,它们的初始位置将随机产生,位置的更新公式为
(9) $X_{i,j}^{t+1}=\left\{ \begin{align} & X_{best}^{t}+\beta \cdot \left| X_{i,j}^{t}-X_{best}^{t} \right|{{f}_{i}}>{{f}_{g}} \\ & X_{i,j}^{t}+K\cdot \frac{\left| X_{i,j}^{t}-X_{worst}^{t} \right|}{({{f}_{i}}-{{f}_{w}})+\varepsilon }{{f}_{i}}={{f}_{g}} \\ \end{align} \right.$
式中,i 表示意识到危险的麻雀数量;β 表示服从均值为0,方差为1的正态分布中生成的随机数;K 表示在范围[-1,1]内生成的随机数,正负符号表示麻雀的移动方向,而数值大小则表示移动的步长控制参数。fi 表示当前个体的适应度值;fg 表示当前最大适应度值;fw 表示当前最小适应度值。
步骤5:在每轮迭代后,检查是否满足停止条件,如果满足,输出最佳麻雀位置,否则回到步骤2重新开始搜索。
2.5 注意力机制
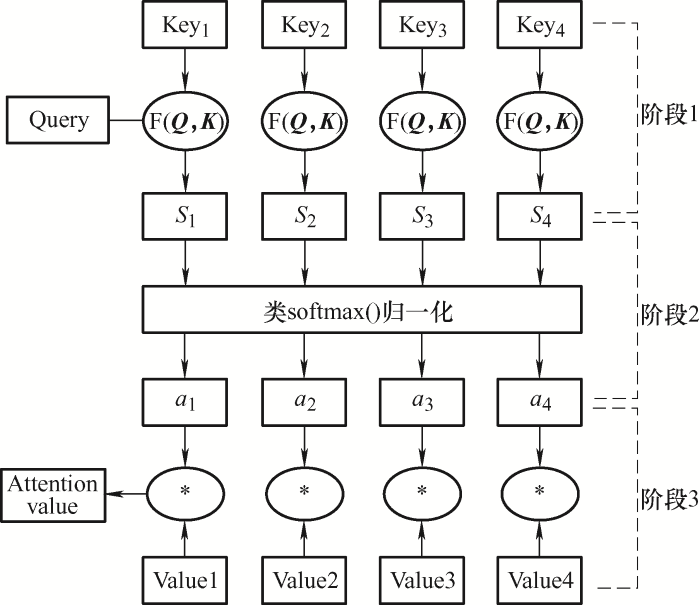
注意力机制逐渐成为目前深度学习领域的主流方法和研究热点之一[24 ] 。注意力机制通过模拟人类处理信息的方式,允许模型在处理输入数据时选择性地关注不同部分,通过一种概率分配的方式对输入数据中的不同部分分配不同的关注度,从而突出重要信息的影响,以便更好地理解和处理信息。将LSTM网络和注意力机制结合,通过Attention挖掘数据内部的相关性。LSTM模型包括三个LSTM层,VMD二次分解得到的模态作为第一个LSTM层的输入量,第三个LSTM层的输出序列及负荷影响因素如温度、湿度、风力等数据作为注意力机制(Attention)的输入,得到注意力权重。将注意力权重应用到输入张量上,得到单一模态分量的预测结果,将VMD分解得到的各模态分量的预测结果相加,得到最终预测结果。注意力机制的模型结构如图2 所示,其本质为根据Q K
图2
第1阶段:Query与Keyi Si 。
第2阶段:对Si 进行softmax()归一化得到ai 。
第3阶段:将ai 与Valuei 对应相乘再求和,得到最终的Attention value,完成对Value矩阵中值的再分配。
(10) $\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left( \frac{Q{{K}^{\mathrm{T}}}}{\sqrt{{{d}_{k}}}} \right)v$
2.6 EMD-SSA-VMD-LSTM-Attention模型
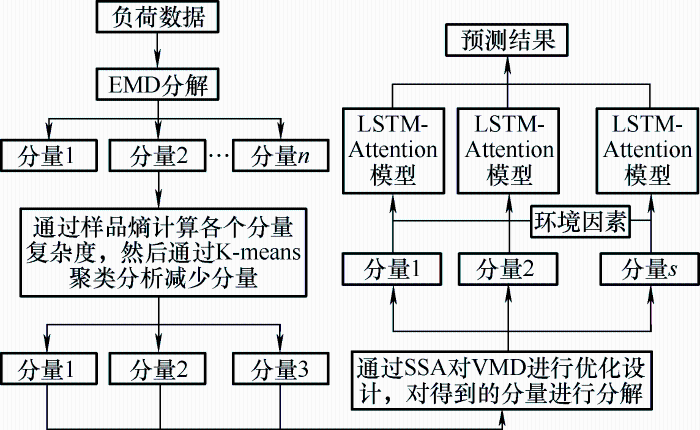
针对电力系统负荷数据非线性强的特点,为了更好捕捉负荷数据的潜在模态和趋势,降低噪声和干扰的影响,对负荷数据进行两次分解。为了更好捕捉负荷数据中的长期依赖关系,增加模型动态适应性,在负荷预测模型中加入LSTM网络。针对负荷数据受环境和社会因素影响多的特点,在负荷预测模型中加入注意力机制挖掘数据内部的相关性。为了减少模型中的噪声和冗余信息,同时为了解决二次分解产生的模态数量过多的问题,通过样本熵计算分量复杂度,然后通过K-means算法根据样本熵的不同类别将其重组得到三个分量。VMD分解是一种完全非递归的迭代优化方法,采用麻雀搜索算法对VMD分解的模态数、正则化参数及迭代次数等参数进行优化,同时采用麻雀搜索算法对LSTM网络中的隐藏层神经元个数、丢弃率及批次大小等参数进行优化。
综上提出EMD-SSA-VMD-LSTM-Attention负荷预测模型的流程图如图3 所示,该结构包含数据预处理、EMD分解、样本熵计算分量复杂度、K-means聚类分析减少分量、VMD二次分解、LSTM-Attention模型预测、得到预测结果并分析误差等部分,其中LSTM模型包括三个LSTM 层和一个全连接层及Dropout层,使用MAE作为损失函数,Adam作为优化器,通过早停法防止模型过拟合。
图3
图3
基于双模态分解的发电站母线短期负荷预测流程图
3 模型仿真与结果分析
3.1 数据预处理
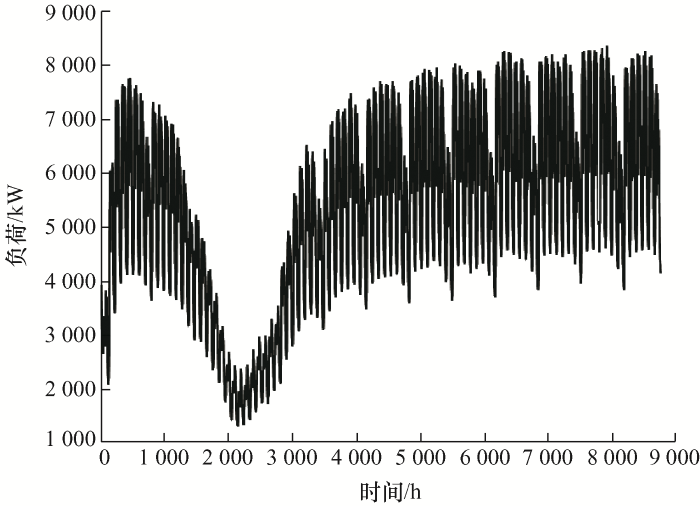
试验采用宁夏某电站2021年1月1日到2021年12月31日的母线负荷数据进行测试,数据采集间隔为1 h,共8 760条数据,母线负荷数据如图4 所示,可以看出负荷数据大致在5 500 kW。数据集包含母线负荷、温度、湿度和风力等负荷相关数据特征,以8∶2的比例划分训练集和测试集。首先对数据进行处理,将采集到的负荷数据和负荷相关数据进行数据清洗,以天为单位剔除采集到的不合理数据。具体处理方法为通过均方值法找出异常点,然后通过相近两点数据的平均值进行替换。均方值法计算公式为
(11) $\left\{ \begin{align} & u=\sum\limits_{i=1}^{N}{\frac{{{y}_{i}}}{N}} \\ & {{\delta }^{2}}=\sum\limits_{i=1}^{N}{\frac{{{({{y}_{i}}-u)}^{2}}}{N-1}} \\ \end{align} \right.$
式中,N 为采集负荷数据的次数;yi 为第i 次采集到负荷数据值,若$\left| {{y}_{i}}-u \right|>3\delta $
图4
3.2 仿真数据展示
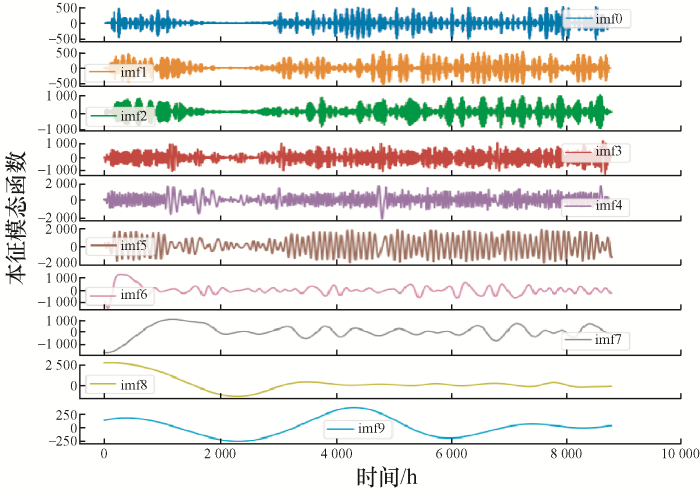
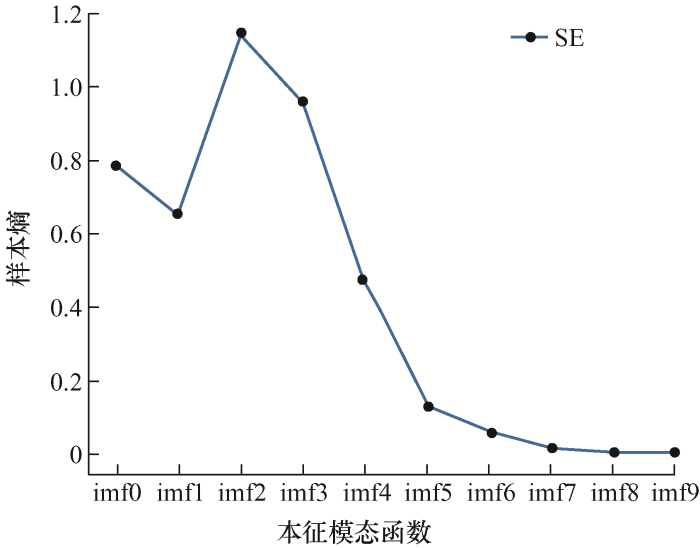
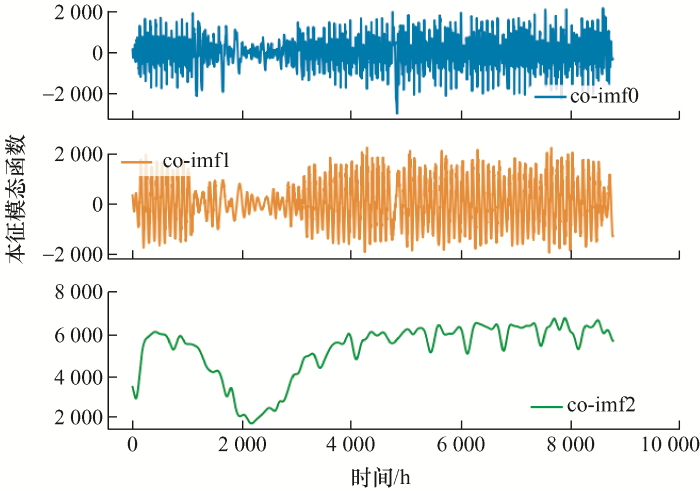
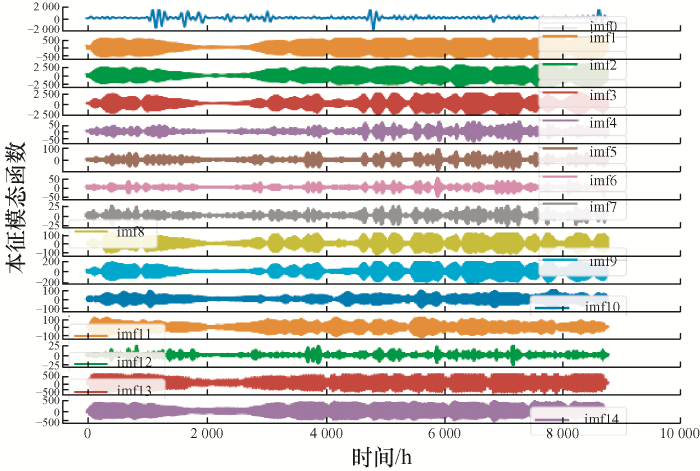
图5 为对采集到的负荷数据进行EMD分解得到的10个本征模态函数。图6 为对EMD分解得到的10个本征模态函数的样本熵。图7 通过K-means算法重组得到的三个分量,图8 为对K-means算法得到的分量进行VMD再次分解后得到的15个本征模态函数。
图5
图6
图7
图8
3.3 评价指标
试验采用多个评价指标来评估负荷预测模型的性能。这些指标包括均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分误差(MAPE)以及决定系数(R 2 )。各个标准对应公式如下
(12) $\mathrm{RMSE}=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}{{{({{y}_{i}}-{{{\hat{y}}}_{i}})}^{2}}}}$
(13) $\mathrm{MAPE}=\frac{1}{n}\sum\limits_{i=1}^{n}{\frac{|{{y}_{i}}-{{{\hat{y}}}_{i}}|}{{{y}_{i}}}}\times 100%$
(14) ${{R}^{2}}=1-\frac{\sum\limits_{i=1}^{n}{{{({{y}_{i}}-{{{\hat{y}}}_{i}})}^{2}}}}{\sum\limits_{i=1}^{n}{{{({{y}_{i}}-{{{\bar{y}}}_{i}})}^{2}}}}$
(15) $\mathrm{MAE}=\frac{1}{n}\sum\limits_{i=1}^{n}{\left| {{y}_{i}}-{{{\hat{y}}}_{i}} \right|}$
式中,yi 为第i 次采样的负荷值;${{\hat{y}}_{i}}$ n 为预测点个数。RMSE、MAE、MAPE越小,试验效果越好,R 2 越大试验效果越好。
3.4 结果分析
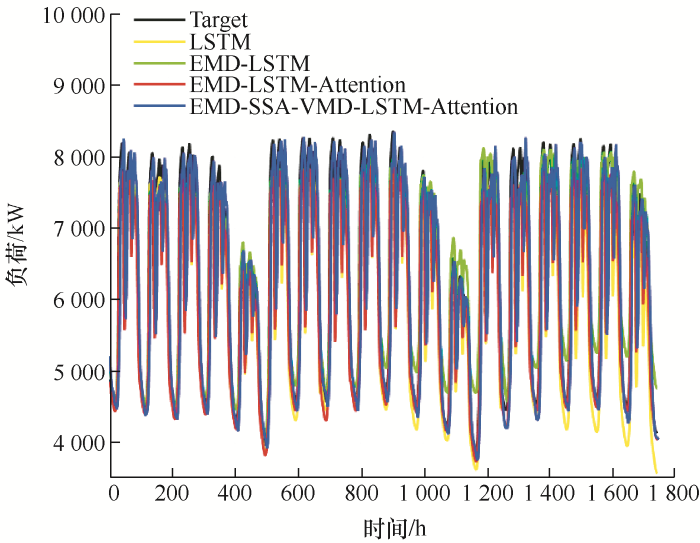
为验证预测模型的准确性,将EMD-SSA-VMD- LSTM-Attention模型的运行结果与相同输入数据的LSTM、EMD-LSTM、EMD-LSTM-Attention模型运行结果进行对比,得到预测模型结果对比如表1 所示。
由表1 可得出如下结论:① 试验各模型中MAPE最低为4.06%,最高为6.06%;RMSE最低为285.6 kW,最高为463.7 kW;MAE最低为214.8 kW,最高为377.9 kW;② EMD-SSA- VMD- LSTM-Attention模型相较其他模型有更低的MAPE、RMSE、MAE和更高的预测准确率;③ 对比EMD-LSTM-Atttenion模型与EMD-LSTM模型的试验结果可知,EMD-LSTM-Atttenion模型表现更好,说明加入注意力机制对负荷预测精度的提升是有益的;④ 对比EMD-SSA-VMD-LSTM-Attention模型与EMD-LSTM-Atttenion模型的试验结果可知,EMD-SSA-VMD-LSTM-Attention模型表现更好,说明加入注意力机制对负荷预测精度的提升是有益的。图9 为试验中发电站母线负荷实际值和四种模型预测值的曲线对比图,通过对比可以更加明晰地看到各个模型的预测结果与实际值的差距。
图9
4 结论
母线负荷预测是电力系统运营和规划中至关重要的一项任务,为了提升负荷预测的精度,针对母线负荷数据的不稳定性、非线性强和环境影响大的特点,本文提出了一种基于双模态分解、深度学习和注意力机制的EMD-SSA-VMD-LSTM-Attention模型。首先,将预处理得到的数据通过VMD分解成多个模态分量,使用样本熵对每个分量的复杂度进行计算,然后通过K-means聚类分析对复杂度相似的分量进行集合得到三个组合分量。其次,使用VMD对组合分量进行二次分解,并使用SSA算法优化VMD。最后,将采集到的负荷影响因素如温度、湿度、风力等数据和VMD分解得到的模态分量输入到长短期网络中,并通过注意力机制挖掘数据内部的相关性,最终通过数据重构得到负荷结果。试验采用宁夏某电站的母线负荷数据进行测试,其中包括了母线负荷、温度、湿度、风力等负荷影响因素的信息。
通过EMD-SSA-VMD-LSTM-Attention 模型与不同模型的试验结果对比可以看到,本文提出的模型在精确度方面有更好的表现;RMSE相对其他模型降低178.1 kW、123.8 kW、54.7 kW,MAE相对其他模型降低了163.1 kW、140.3 kW、48.4 kW,MAPE 相对其他模型降低了2%、0.82%、0.29%,R 2 相对其他模型增加了6.5%、4.1%、1.3%。基于该研究方向,接下来计划在模型加入更多的负荷影响因素,对模型涉及到的算法进行改进,提高预测准确性的同时减少模型预测运行的时间。
参考文献
View Option
[1]
张雲钦 , 程起泽 , 蒋文杰 , 等 . 基于EMD-PCA-LSTM的光伏功率预测模型
[J]. 太阳能学报 , 2021 , 42 (9 ):62 -69 .
[本文引用: 5]
ZHANG Yunqin CHENG Qize JIANG Wenjie et al. A photovoltaic power prediction model based on EMD-PCA-LSTM
[J]. Acta Energiae Solaris Sinica , 2021 , 42 (9 ):62 -69 .
[本文引用: 5]
[2]
刘鑫 , 滕欢 , 宫毓斌 , 等 . 基于改进卡尔曼滤波算法的短期负荷预测
[J]. 电测与仪表 , 2019 , 56 (3 ):42 -46 .
[本文引用: 1]
LIU Xin TENG Huan GONG Yubin et al. Short-term load forecasting based on the improved Kalman filter algorithm
[J]. Electrical Measurement & Instrumentation , 2019 , 56 (3 ):42 -46 .
[本文引用: 1]
[3]
廖旎焕 , 胡智宏 , 马莹莹 , 等 . 电力系统短期负荷预测方法综述
[J]. 电力系统保护与控制 , 2011 , 39 (1 ):147 -152 .
[本文引用: 1]
LIAO Nihuan HU Zhihong MA Yingying et al. Review of short term load forecasting methods for power systems
[J]. Power System Protection and Control , 2011 , 39 (1 ):147 -152 .
[本文引用: 1]
[4]
耿光飞 , 郭喜庆 . 模糊线性回归法在负荷预测中的应用
[J]. 电网技术 , 2002 , 26 (4 ):19 -21 .
[本文引用: 1]
GENG Guangfei QUO Xiqing Application of fuzzy linear regression to load forecasting
[J]. Power System Technology , 2002 , 26 (4 ):19 -21 .
[本文引用: 1]
[5]
吴迪 , 马文莉 , 杨利君 . 二次指数平滑多目标组合模型电力负荷预测
[J]. 计算机工程与设计 , 2023 , 44 (8 ):2541 -2547 .
[本文引用: 1]
WU Di MA Wenli YANG Lijun Second order exponential smoothing multi objective combination model for power load forecasting
[J]. Computer Engineering and Design , 2023 , 44 (8 ):2541 -2547 .
[本文引用: 1]
[6]
李江 , 王义伟 , 魏超 , 等 . 卡尔曼滤波理论在电力系统中的应用综述
[J]. 电力系统保护与控制 , 2014 , 42 (6 ):135 -144 .
[本文引用: 1]
LI Jiang WANG Yiwei WEI Chao et al. Review of the application of Kalman filter theory in power systems
[J]. Power System Protection and Control , 2014 , 42 (6 ):135 -144 .
[本文引用: 1]
[7]
FUMO N BISWAS M A R Regression analysis for prediction of residential energy consumption
[J]. Renewable and Sustainable Energy Reviews , 2015 ,47:332 -343 .
[本文引用: 1]
[8]
朱亚玲 . 基于改进高斯过程回归的负荷预测模型研究 [D]. 淄博 : 山东理工大学 , 2023 .
[本文引用: 1]
ZHU Yaling Research on load forecasting model based on improved Gaussian process regression [D]. Zibo : Shandong University of Technology , 2023 .
[本文引用: 1]
[9]
周思思 , 李勇 , 郭钇秀 , 等 . 考虑时序特征提取与双重注意力融合的TCN超短期负荷预测
[J]. 电力系统自动化 , 2023 , 47 (18 ):193 -205 .
[本文引用: 1]
ZHOU Sisi LI Yong GUO Yixiu et al. Ultra-short-term load forecasting based on temporal convolutional network considering temporal feature extraction and dual attention fusion
[J]. Automation of Electric Power Systems , 2023 , 47 (18 ):193 -205 .
[本文引用: 1]
[10]
付文杰 , 李化 , 杨伯青 , 等 . 基于集合卡尔曼滤波与相空间重构的负荷预测方法研究
[J]. 电力需求侧管理 , 2022 , 24 (1 ):49 -54 .
[本文引用: 1]
FU Wenjie LI Hua YANG Boqing et al. Research on load forecasting method based on set Kalman filter and phase space reconstruction
[J]. Power Demand Side Management , 2022 , 24 (1 ):49 -54 .
[本文引用: 1]
[11]
杜伟春 , 罗宏波 , 杨楠 . 改进灰色预测模型在电力负荷预测中的应用
[J]. 湖南电力 , 2023 , 43 (3 ):88 -93 .
DOI:10.3969/j.issn.1008-0198.2023.03.014
[本文引用: 1]
传统的灰色电力负荷预测模型存在预测精度低的缺陷,以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度。针对原始数据中可能存在异常数据导致的预测结果精度较低的问题,采用对原始数据进行平滑处理的方法,以降低异常数据对预测结果干扰的影响;考虑到传统GM(1,1)模型中的初始值通常选择的是历史数据中最早一年的数据,存在与未来关系不密切且规律性低的问题,采用历史数据中最新一年的数据作为预测模型的初始值;采用残差处理的方法对原模型进行修正,以提高预测精度。综合考虑上述三种改进方法,对传统灰色系统的GM(1,1)模型进行改进。基于某地区实际算例的仿真结果表明,相对于传统的灰色预测模型,改进后的模型预测结果精度大大提高,验证了改进措施的有效性。
DU Weichun LUO Hongbo YANG Nan Application of improved grey prediction model in power load forecasting
[J]. Hunan Electric Power , 2023 , 43 (3 ):88 -93 .
DOI:10.3969/j.issn.1008-0198.2023.03.014
[本文引用: 1]
The traditional grey prediction model has the defect of low prediction accuracy. Based on the GM (1,1) model in the grey system, this paper analyzes the limitations of the model and gives solutions to improve the accuracy of load forecasting. Aiming at the problem that there may be abnormal data in the original data, which leads to the low accuracy of the prediction results, this paper adopts the method of smoothing the original data to reduce the influence of abnormal data on the prediction results. Considering that the initial value of the traditional GM (1,1) model usually selects the data of the earliest one year in the historical data, which is not closely related to the future and has low regularity, this paper uses the data of the latest one year in the historical data as the initial value of the prediction model. The residual processing method is used to modify the original model to improve the prediction accuracy. Considering the above three improvement methods, the GM (1,1) model of the traditional system is improved. The simulation results based on a practical example in a certain area show that compared with the traditional grey prediction model, the prediction accuracy of the improved prediction model is greatly improved, which verifies the effectiveness of the improvement measures.
[12]
NOBLE W S What is a support vector machine?
[J]. Nature Biotechnology , 2006 , 24 (12 ):1565 -1567 .
DOI:10.1038/nbt1206-1565
PMID:17160063
[本文引用: 1]
Support vector machines (SVMs) are becoming popular in a wide variety of biological applications. But, what exactly are SVMs and how do they work? And what are their most promising applications in the life sciences?
[14]
程宇也 . 基于人工神经网络的短期电力负荷预测研究 [D]. 杭州 : 浙江大学 , 2017 .
[本文引用: 1]
CHENG Yuye Research on short term power load forecasting based on artificial neural networks [D]. Hangzhou : Zhejiang University , 2017 .
[本文引用: 1]
[15]
MOHANDES M Support vector machines for short-term electrical load forecasting
[J]. International Journal of Energy Research , 2002 , 26 (4 ):335 -345 .
DOI:10.1002/(ISSN)1099-114X
URL
[本文引用: 1]
[16]
杨秀媛 , 肖洋 , 陈树勇 . 风电场风速和发电功率预测研究
[J]. 中国电机工程学报 , 2005 , 25 (11 ):1 -5 .
[本文引用: 1]
YANG Xiuyuan XIAO Yang CHEN Shuyong Wind speed and generated power forecasting in wind farm
[J]. Proceedings of the CSEE , 2005 , 25 (11 ):1 -5 .
[本文引用: 1]
[17]
ZOU H YANG Q CHEN J et al. Short-term power load forecasting based on phase space reconstruction and EMD-ELM
[J]. Journal of Electrical Engineering & Technology , 2023 (5 ):1 -11 .
[本文引用: 1]
[18]
陈卓 , 孙龙祥 . 基于深度学习LSTM网络的短期电力负荷预测方法
[J]. 电子技术 , 2018 , 47 (1 ):39 -41 .
[本文引用: 2]
CHEN Zhuo SUN Longxiang Short term power load forecasting method based on deep learning LSTM network
[J]. Electronic Technology , 2018 , 47 (1 ):39 -41 .
[本文引用: 2]
[19]
杨汪洋 , 魏云冰 , 罗程浩 . 基于CVMD-TCN-BiLSTM的短期电力负荷预测
[J/OL]. 电气工程学报 :1 -10 [2023-09-26]. http://kns.cnki.net/kcms/detail/10.1289.TM.20230601.1229.002.html
URL
[本文引用: 1]
YANG Wangyang WEI Yunbing LUO Chenghao Short term power load prediction based on CVMD-TCN-BiLSTM
[J/OL]. Journal of Electrical Engineering:1-10 ,[2023-09-26]. http://kns.cnki.net/kcms/detail/10.1289.TM.20230601.1229.002.html
URL
[本文引用: 1]
[20]
穆晨宇 , 薛文斌 , 穆羡瑛 , 等 . 基于VMD-LSTM- Attention模型的短期负荷预测研究
[J]. 现代电子技术 , 2023 , 46 (17 ):174 -178 .
[本文引用: 1]
MU Chenyu XUE Wenbin MU Xianying et al. Research on short term load forecasting based on VMD-LSTM- Attention model
[J]. Modern Electronic Technology , 2023 , 46 (17 ):174 -178 .
[本文引用: 1]
[21]
王婷 . EMD算法研究及其在信号去噪中的应用 [D]. 哈尔滨 : 哈尔滨工程大学 , 2011 .
[本文引用: 1]
WANG Ting Research on EMD algorithm and its application in signal denoising [D]. Harb in:Harbin Engineering University, 2011 .
[本文引用: 1]
[22]
刘建昌 , 权贺 , 于霞 , 等 . 基于参数优化VMD和样本熵的滚动轴承故障诊断
[J]. 自动化学报 , 2022 , 48 (3 ):808 -819 .
[本文引用: 1]
LIU Jianchang QUAN He YU Xia et al. Fault diagnosis of rolling bearings based on parameter optimization VMD and sample entropy
[J]. Acta Automatica Sinica , 2022 , 48 (3 ):808 -819 .
[本文引用: 1]
[23]
李晓淞 , 黄茜 , 郭木涵 , 等 . 基于麻雀搜索算法优化BP神经网络的短期负荷预测
[J]. 信息记录材料 , 2023 , 24 (6 ):224 -227 .
[本文引用: 1]
LI Xiaosong HUANG Qian GUO Muhan et al. Short term load forecasting based on sparrow search algorithm optimized BP neural network
[J]. Information Recording Materials , 2023 , 24 (6 ):224 -227 .
[本文引用: 1]
[24]
朱张莉 , 饶元 , 吴渊 , 等 . 注意力机制在深度学习中的研究进展
[J]. 中文信息学报 , 2019 , 33 (6 ):1 -11 .
[本文引用: 1]
注意力机制逐渐成为目前深度学习领域的主流方法和研究热点之一,它通过改进源语言表达方式,在解码中动态选择源语言相关信息,从而极大改善了经典Encoder-Decoder框架的不足。该文在提出传统基于Encoder-Decoder框架中存在的长程记忆能力有限、序列转化过程中的相互关系、模型动态结构输出质量等问题的基础上,描述了注意力机制的定义和原理,介绍了多种不同的分类方式,分析了目前的研究现状,并叙述了目前注意力机制在图像识别、语音识别和自然语言处理等重要领域的应用情况。同时,进一步从多模态注意力机制、注意力的评价机制、模型的可解释性及注意力与新模型的融合等方面进行了探讨,从而为注意力机制在深度学习中的应用提供新的研究线索与方向。
ZHU Zhangli RAO Yuan WU Yuan et al. Research progress on Attention mechanisms in deep learning
[J]. Journal of Chinese Information Processing , 2019 , 33 (6 ):1 -11 .
[本文引用: 1]
The attention mechanism has gradually become one of the popular methods and research issues in deep learning. By improving the source language expression, it dynamically selects the related information of the source language in decoding, which greatly improves the insufficiency issue of the classic Encoder-Decoder framework. On the basis of the issues in the conventional Encoder-Decoder framework such as long-term memory limitation, interrelationships in sequence transformation, and output quality of model dynamic structure, this paper describes a varied aspects on attention mechanism, including the definition, the principle, the classification, state-of-the-art researches as well as the applications of attention mechanism in image recognition, speech recognition, and natural language processing. Meanwhile, this paper further discusses the multi-modal attention mechanism, evaluation mechanism of attention, interpretability of the model and integration of attention with the new model, providing new research issues and directions for the development of attention mechanism in deep learning.
基于EMD-PCA-LSTM的光伏功率预测模型
5
2021
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
... 式中,i 为发现者;$x_{i,j}^{t}$ i 只麻雀在第t 次迭代时的位置的j 维坐标;a 为[0,1 ]的随机数;R 2 为[0,1 ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
... 为[0,1 ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
... ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
A photovoltaic power prediction model based on EMD-PCA-LSTM
5
2021
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
... 式中,i 为发现者;$x_{i,j}^{t}$ i 只麻雀在第t 次迭代时的位置的j 维坐标;a 为[0,1 ]的随机数;R 2 为[0,1 ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
... 为[0,1 ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
... ]的随机数,表示预警值;ST为[0.5,1 ]的常数,表示安全值.当预警值R 2 <ST时表示是安全的,此时发现者的搜索范围比较大;当预警值R 2 ≥ST时表示有了一定数量的捕食者,需要移动到安全的区域,Q 为服从正态分布的随机数,L d 矩阵,itermax 为最大迭代次数. ...
基于改进卡尔曼滤波算法的短期负荷预测
1
2019
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Short-term load forecasting based on the improved Kalman filter algorithm
1
2019
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
电力系统短期负荷预测方法综述
1
2011
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Review of short term load forecasting methods for power systems
1
2011
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
模糊线性回归法在负荷预测中的应用
1
2002
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Application of fuzzy linear regression to load forecasting
1
2002
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
二次指数平滑多目标组合模型电力负荷预测
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Second order exponential smoothing multi objective combination model for power load forecasting
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
卡尔曼滤波理论在电力系统中的应用综述
1
2014
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Review of the application of Kalman filter theory in power systems
1
2014
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Regression analysis for prediction of residential energy consumption
1
2015
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
考虑时序特征提取与双重注意力融合的TCN超短期负荷预测
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Ultra-short-term load forecasting based on temporal convolutional network considering temporal feature extraction and dual attention fusion
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
基于集合卡尔曼滤波与相空间重构的负荷预测方法研究
1
2022
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Research on load forecasting method based on set Kalman filter and phase space reconstruction
1
2022
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
改进灰色预测模型在电力负荷预测中的应用
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
Application of improved grey prediction model in power load forecasting
1
2023
... 随着相关研究的逐步进行,负荷预测方法大致分为两类:传统的预测方法、基于机器学习和深度学习的方法[1 ] .传统负荷预测有回归分析法、时间序列法、负荷求导法、卡尔曼滤波法、指数平滑法、灰色预测法[2 ⇓ ⇓ ⇓ ⇓ -7 ] 等.这些传统负荷预测方法各有优点和限制,通常适用于不同的预测需求和数据情况.文献[8 ]针对目前常用的共轭梯度法无法准确获取超参数的问题,提出结合蚁狮算法改进的高斯过程回归模型.文献[9 ]从特征构建与模型优化两个角度出发,提出一种基于Prophet和双重多头自注意力-时间卷积网络的超短期负荷预测框架.文献[10 ]提出一种基于集合卡尔曼滤波和相空间重构的组合模型来优化预测结果.文献[11 ]以灰色系统中的GM(1,1)模型为基础,通过分析模型存在的局限性,给出解决方案以提高负荷预测的精度.传统预测方法的可解释性高、建模和计算速度快,但它们对数据质量要求高,且在某些情况下可能会导致较大的误差. ...
What is a support vector machine?
1
2006
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
A tutorial on support vector regression
1
2004
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
1
2017
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
1
2017
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
Support vector machines for short-term electrical load forecasting
1
2002
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
风电场风速和发电功率预测研究
1
2005
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
Wind speed and generated power forecasting in wind farm
1
2005
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
Short-term power load forecasting based on phase space reconstruction and EMD-ELM
1
2023
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
基于深度学习LSTM网络的短期电力负荷预测方法
2
2018
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
... LSTM单元的内部结构如图1 所示.每个LSTM单元有3个门结构:遗忘门、输入门和输出门[18 ] .xt 为t 时刻的输入向量,ct -1 为t -1时刻的记忆单元状态、ht -1 为t -1时刻的隐含层状态,ct -1 和ht -1 为LSTM单元模块t 时刻的输入量.LSTM单元内部信息运行如下所示. ...
Short term power load forecasting method based on deep learning LSTM network
2
2018
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
... LSTM单元的内部结构如图1 所示.每个LSTM单元有3个门结构:遗忘门、输入门和输出门[18 ] .xt 为t 时刻的输入向量,ct -1 为t -1时刻的记忆单元状态、ht -1 为t -1时刻的隐含层状态,ct -1 和ht -1 为LSTM单元模块t 时刻的输入量.LSTM单元内部信息运行如下所示. ...
基于CVMD-TCN-BiLSTM的短期电力负荷预测
1
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
Short term power load prediction based on CVMD-TCN-BiLSTM
1
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
基于VMD-LSTM- Attention模型的短期负荷预测研究
1
2023
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
Research on short term load forecasting based on VMD-LSTM- Attention model
1
2023
... 随着科学技术的不断发展,现代方法如基于机器学习方法的负荷预测正在逐渐取代传统的预测方法,它们更加适合处理复杂和不断变换的负荷数据.基于机器学习负荷预测的方法有人工神经网络算法、支持向量回归算法、长短期记忆网络算法[12 ⇓ ⇓ ⇓ -16 ] 等.文献[17 ]采用麻雀搜索算法优化双向LSTM注意力负荷模型的超参数,预测准确性得到了提升.文献[18 ]采用长短期记忆网络模型进行负荷预测,通过试验证明了长短期记忆网络模型相较于传统模型在精度上有所提升.文献[1 ]提出一种经验模态分解、主成分分析和长短期记忆神经网络相结合的光伏功率预测模型.文献[19 ]针对短期负荷数据中掺杂着多种类型的噪声和波动性大的特点,提出一种分解去噪、重构分解的CVMD-TCN- BiLSTM组合预测方法.文献[20 ]针对负荷数据非线性强以及影响因素多等特点,提出一种基于变分模态分解和注意力机制的长短期记忆网络的组合预测方法. ...
1
2011
... 经验模态分解法(EMD)分解是一种处理非线性、非平稳信号的自适应分解方法[21 ] .它会根据时间序列数据的特性自动生成本征模态函数(IMF),直到数据被分解为不再包含明显的振荡或模式为止.每个IMF表征信号的局部特征,反映负荷数据的波动性、周期性和趋势变化.对负荷数据进行预处理后将其转换为一组一维时间序列数据x (t )并进行EMD分解,将分解得到不同的模态经处理后作为二次分解的输入数据,EMD具体分解步骤如下所示. ...
1
2011
... 经验模态分解法(EMD)分解是一种处理非线性、非平稳信号的自适应分解方法[21 ] .它会根据时间序列数据的特性自动生成本征模态函数(IMF),直到数据被分解为不再包含明显的振荡或模式为止.每个IMF表征信号的局部特征,反映负荷数据的波动性、周期性和趋势变化.对负荷数据进行预处理后将其转换为一组一维时间序列数据x (t )并进行EMD分解,将分解得到不同的模态经处理后作为二次分解的输入数据,EMD具体分解步骤如下所示. ...
基于参数优化VMD和样本熵的滚动轴承故障诊断
1
2022
... 变分模态分解(VMD)利用求解变分问题的思想去对信号进行提取,在不丢失原始信号特征的情况下,把一个原始信号分解成多个不同中心频率的信号,适用于非线性时间序列信号.VMD分解是一种完全非递归的迭代优化方法,需要通过不断迭代优化模态函数来逼近原始信号.通过麻雀搜索算法对VMD分解的模态数、正则化参数及迭代次数等参数进行优化以获取最小化信号重构误差和正则化项,得到最佳的模态函数.样本熵是一种度量时间序列复杂度的方法[22 ] .将EMD分解得到的多个模态通过样本熵计算分量复杂度,然后通过K-means算法将其重组得到三个分量,将三个分量作为VMD分解的输入数据.假设输入信号f (t )能够分解为K 个有限带宽的模态分量,所有模态之和等于原始信号,各模态的估计带宽之和最小,VMD分解的约束变分模型如下 ...
Fault diagnosis of rolling bearings based on parameter optimization VMD and sample entropy
1
2022
... 变分模态分解(VMD)利用求解变分问题的思想去对信号进行提取,在不丢失原始信号特征的情况下,把一个原始信号分解成多个不同中心频率的信号,适用于非线性时间序列信号.VMD分解是一种完全非递归的迭代优化方法,需要通过不断迭代优化模态函数来逼近原始信号.通过麻雀搜索算法对VMD分解的模态数、正则化参数及迭代次数等参数进行优化以获取最小化信号重构误差和正则化项,得到最佳的模态函数.样本熵是一种度量时间序列复杂度的方法[22 ] .将EMD分解得到的多个模态通过样本熵计算分量复杂度,然后通过K-means算法将其重组得到三个分量,将三个分量作为VMD分解的输入数据.假设输入信号f (t )能够分解为K 个有限带宽的模态分量,所有模态之和等于原始信号,各模态的估计带宽之和最小,VMD分解的约束变分模型如下 ...
基于麻雀搜索算法优化BP神经网络的短期负荷预测
1
2023
... 麻雀搜索算法(SSA)是一种基于麻雀觅食行为与反捕食行为的智能优化算法[23 ] .作为一种新兴的启发式优化方法,该算法受到麻雀群体行为的启发,在很多领域中展现出了潜力.通过模拟麻雀集体智慧,麻雀搜索算法为解决复杂的优化问题提供了一种新的视角和有效的求解策略.麻雀搜索算法将麻雀群分为发现者、跟随者和警戒者三种类型,其中找到较好食物的个体作为发现者,发现者觅食并为种群提供觅食信息;跟随者通过发现者发出的信息进行觅食和位置更新;种群中意识到危险的麻雀作为警戒者,遇到危险时发出信息防备天敌.通过麻雀搜索算法可以对VMD和LSTM网络中的参数进行优化,SSA步骤如下所示. ...
Short term load forecasting based on sparrow search algorithm optimized BP neural network
1
2023
... 麻雀搜索算法(SSA)是一种基于麻雀觅食行为与反捕食行为的智能优化算法[23 ] .作为一种新兴的启发式优化方法,该算法受到麻雀群体行为的启发,在很多领域中展现出了潜力.通过模拟麻雀集体智慧,麻雀搜索算法为解决复杂的优化问题提供了一种新的视角和有效的求解策略.麻雀搜索算法将麻雀群分为发现者、跟随者和警戒者三种类型,其中找到较好食物的个体作为发现者,发现者觅食并为种群提供觅食信息;跟随者通过发现者发出的信息进行觅食和位置更新;种群中意识到危险的麻雀作为警戒者,遇到危险时发出信息防备天敌.通过麻雀搜索算法可以对VMD和LSTM网络中的参数进行优化,SSA步骤如下所示. ...
注意力机制在深度学习中的研究进展
1
2019
... 注意力机制逐渐成为目前深度学习领域的主流方法和研究热点之一[24 ] .注意力机制通过模拟人类处理信息的方式,允许模型在处理输入数据时选择性地关注不同部分,通过一种概率分配的方式对输入数据中的不同部分分配不同的关注度,从而突出重要信息的影响,以便更好地理解和处理信息.将LSTM网络和注意力机制结合,通过Attention挖掘数据内部的相关性.LSTM模型包括三个LSTM层,VMD二次分解得到的模态作为第一个LSTM层的输入量,第三个LSTM层的输出序列及负荷影响因素如温度、湿度、风力等数据作为注意力机制(Attention)的输入,得到注意力权重.将注意力权重应用到输入张量上,得到单一模态分量的预测结果,将VMD分解得到的各模态分量的预测结果相加,得到最终预测结果.注意力机制的模型结构如图2 所示,其本质为根据Q K
Research progress on Attention mechanisms in deep learning
1
2019
... 注意力机制逐渐成为目前深度学习领域的主流方法和研究热点之一[24 ] .注意力机制通过模拟人类处理信息的方式,允许模型在处理输入数据时选择性地关注不同部分,通过一种概率分配的方式对输入数据中的不同部分分配不同的关注度,从而突出重要信息的影响,以便更好地理解和处理信息.将LSTM网络和注意力机制结合,通过Attention挖掘数据内部的相关性.LSTM模型包括三个LSTM层,VMD二次分解得到的模态作为第一个LSTM层的输入量,第三个LSTM层的输出序列及负荷影响因素如温度、湿度、风力等数据作为注意力机制(Attention)的输入,得到注意力权重.将注意力权重应用到输入张量上,得到单一模态分量的预测结果,将VMD分解得到的各模态分量的预测结果相加,得到最终预测结果.注意力机制的模型结构如图2 所示,其本质为根据Q K




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}