1 引言
低压配电系统的线损管理是电力系统线损管理的重要组成部分,涉及配电系统的规划、运行、营销和计量。统计的线损包含管理线损,但由于低压配电系统网络结构复杂、用户数量多、性质复杂、海量数据管理困难等原因,低压配电系统线损计算存在较大偏差[1 ] 。理论线损的计算是基于电网设备参数、操作数据和功率流以及载荷分布理论,它可以准确地了解电网损耗的构成,并且提供一个可靠的依据充分利用电网企业的潜在 损失。
配电网处于发电、输电、配电的末端,其设备数量多、覆盖范围广、电压等级低,导致配电网损耗大。到目前为止,低压配电系统的线损仅根据用户文件进行简单计算,未考虑负荷、供电半径的影响。此外,目前的计算周期一般都是按日计算,当运行方式发生变化时,无法进行实时线损计算[2 ] 。随着分布式可再生能源的广泛集成,低压配电系统中的潮流、线损、电压分布发生了变化,对低压配电系统的线损管理产生了很大的影响。
配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] 。这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] 。近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系。文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度。
为此,本文提出了一种基于K-Means聚类算法和多分类相关向量机(Multi classification correlation vector machine,MRVM)的线损快速计算方法。首先选取与配电网线损有关的电气指标作为模型的输入;针对指标接近,但网架结构和负载特性会影响线损率的情况,本文采用K-Means聚类算法对台区进行聚类分析,简化数据处理,对每一类台区进行具体分析;然后搭建果蝇算法优化MRVM的模型,计算台区线损。以四川资阳供电公司为例,对配电网理论进行了理论在线损耗计算,并与传统理论线损计算结果和综合电力线损管理系统进行了对比,验证了该方法的有 效性。
2 模型输入特征参量选取
为了改善多分类相关向量机的性能,需要优化输入参数,减少维度。通过现场经验和相关电力系统理论知识得知影响台区线损率的参数有供电半径、线路长度、负载率、用电性质、三项不平衡度、电压等,考虑参数的影响大小及获取难易程度,选取与低压台区线损率密切相关的4个电气参数作为输入。通过反复筛选,选取了供电半径、线路总长、负载率以及用电种类及用电种类占比情况[8 ] ,由于研究的是低压台区线损,因此选用居民用电性质来表示用电性质。
(1) 供电半径X1 (m)。供电半径指的是最远的用户到电源点的线路长度,一般用于控制线路电压降,是判断供电半径是否正确的重要参数。
(2) 低压线路长度X2 (m)。低压线路长度指的是所有低压台区线路总长。
(3) 负载率X3 (%)。负载率表示该变压器实际承担的负荷与额定容量之比,用于反映变压器的承载能力。
(4) 用电性质比例X4 (%)。用电性质比例表示负荷用电性质与供电量的比例,能够反映所在台区的用电性质。
选取上述4种参数作为MRVM的输入,由于4中变量的量纲不同,对其进行标准化处理,处理方法如式(1)~(3)所示
(1) $Z_{i j}=x_{i j}-\bar{x}_{j} / \sqrt{S_{i j}}$
(2) $\bar{x}_{j}=\frac{1}{N} \sum_{i=1}^{N} x_{i j}$
(3) $s_{i j}=\frac{1}{N-1} \sum_{i=1}^{N}\left(x_{i j}-\bar{x}_{j}\right)^{2}$
式中,Zij 表示标准量;$\bar{x}_{j}$表示xij 的均值;sij 表示xij 的方差。
3 基于系统聚类和果蝇优化MRVM的低压台区线损计算
3.1 K-Means聚类算法
为了减少网架结构带来的计算误差,需要对台区样本进行聚类分析。在对其进行聚类前,首先要计算样本之间的相似度,一般用距离来表示相似度。本文采用K-Means聚类算法来对台区进行聚类分析,该算法以距离作为相似性的评价指标,以误差平方和准则函数作为聚类准则函数,是一种迭代求解的聚类分析算法,该算法步骤如下[9 ] 所示。
(2) 类划分:按照式(4)计算每个点到K 个聚类中心的距离,然后将该点分到最近的聚类中心,这样就形成了K 个簇。
(4) $L_{i j}=\sqrt{\sum_{k=1}^{m}\left(Z_{i k}-Z_{j k}\right)^{2}}$
(3) 中心点计算:再重新计算每个簇的质心(均值),以此作为聚类中心。
(4) 迭代计算:重复以上步骤(2)~(4),直到质心的位置不再发生变化或者达到设定的迭代次数,用式(5)判断是否收敛。
(5) $E=\sum_{i=1}^{k} \sum_{Z_{q} \in C_{i}}\left(Z_{q}-m_{i}\right)^{2}$
式中,mi 表示Ci 的中心簇;Zq 表示其样本。不断进行迭代计算,直到E 值收敛。
(1) K 值需要预先给定,然而K 值是很难估计的,并且对噪音和异常点十分敏感。
(2) K-Means算法对初始给定的质心十分敏感,选取不同的中心点,会得到不同的聚类结果。
为了解决以上问题,本文通过聚类结果的轮廓系数St 确定K 的大小,轮廓系数的计算方法如式(6)所示[10 ]
(6) $S(i)=\frac{p(i)-q(i)}{\max \{q(i), p(i)\}}$
式中,q(i)表示点i 到所在类别其他点的平均距离;p(i)表示该点到非所在类别中其他点的距离最小值。计算S(i)的均值作为St ,St 越大,表示聚类效果越好,即
(7) $S_{t}=\frac{1}{N} \sum_{i=1}^{N} S(i)$
为了解决局部收敛问题,可以多次随机选取聚类中心,最后比较各自完成后的畸变函数值,畸变函数越小,则说明聚类效果更优[11 ] 。
本文选取低压台区供电半径,低压线路总长,负载率以及用电比例最小值作为电气指标值,台区评价指标如式(8)所示[12 ]
(8) $P_{E}=\sqrt{\sum_{j=1}^{m} \omega_{j}\left(Z_{i j}-Z_{j \min }\right)^{2}} \quad i=1,2, \cdots, N$
式中,$Z_{j \min }=\min _{i \in[1, N]} Z_{i j}$,$\omega_{j}$表示该电气指标的权值,这里赋值1。
可以看出,参数PE 可以反映线损,并且变化趋势相同,因此,可根据PE 的值将样本分为k 组,让每组的中心作为初始聚类中心。
3.2 多分类相关向量机
多分类相关向量机(MRVM)是在相关向量机(RVM)的基础上进行了扩展,该算法相关向量数量少,泛化能力强,可解决小样本、非线性问题。MRVM使用分层贝叶斯模型,能以概率形式给出结果,便于分析问题的不确定性[13 ] 。
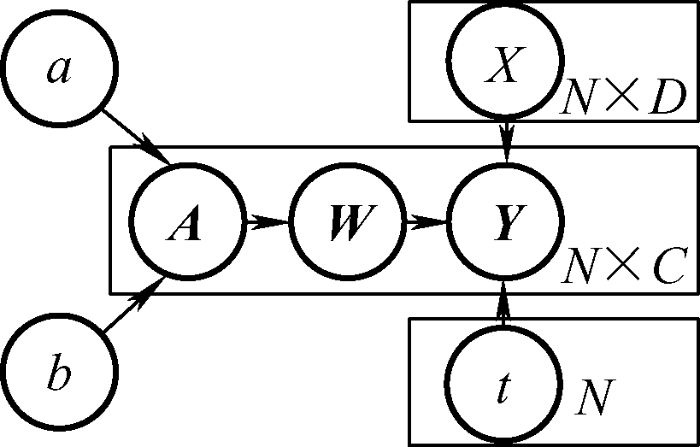
假设输入向量为$\boldsymbol{X}=\left\{x_{i}, t_{i}\right\}_{\neq 1}^{N}$,且$x \in R^{D}$,$t_{i} \in\{1, \cdots, C\}$表示类别标号,核函数为$\boldsymbol{K}=\left[K_{1} \cdots K_{2 \mathrm{~V}}^{\mathrm{T}}, \quad \boldsymbol{K} \in R^{N \times N}\right.$,设辅助回归目标和权重参数分别为$\boldsymbol{Y} \in R^{C \times N}$,$\boldsymbol{W} \in R^{C \times N}$,由此可计算回归模型如式(9)所示
(9) $y_{n c} \mid w_{c}, k_{n} \sim N_{y_{n c}}\left(k_{n} w_{c}, 1\right)$
式中,ync 表示矩阵Y 的n 行c 列;wc 表示矩阵W的第c 列;Nx (m,v)表示变量x 服从正态分布。设多项概率联系函数$t_{n}=i, y_{n}>y_{n j} \forall j \neq i$,则多项概率似然函数公式为[14 ]
(10) $\begin{array}{c}P\left(t_{n}=i \mid W, K_{n}\right)= \left.\varepsilon_{p(u)}\{\prod_{j \neq i} \Phi\left(u+k_{n}\left(W_{i}-W_{j}\right)\right)\right\}\end{array}$
式中,u 服从均值为0,方差为1的正态分布,为了提高模型的稀疏性,使$\alpha_{n c}$服从超参数分别为a ,b 的Gamma分布[15 ] 。MRVM采用分层贝叶斯模型结构,由上述可知其模型结构如图1 所示。
图1
(11) $\begin{array}{c}P(\boldsymbol{W} \mid \boldsymbol{Y}) \propto P(\boldsymbol{Y} \mid \boldsymbol{W}) P(\boldsymbol{W} \mid \boldsymbol{A}) \propto \prod_{c=1}^{c} N\left(\left(\boldsymbol{K} \boldsymbol{K}^{\mathrm{T}}+\boldsymbol{A}_{\varepsilon}\right)^{-1} \boldsymbol{K} \boldsymbol{y}_{c}^{\mathrm{T}},\left(\boldsymbol{K} \boldsymbol{K}^{\mathrm{T}}+\boldsymbol{A}_{c}\right)^{-1}\right)\end{array}$
由此可的最大后验概率为$\hat{W}=\arg \max _{W}P(\boldsymbol{W} \mid \boldsymbol{Y}, \boldsymbol{A}, \boldsymbol{K})$,当类别确定,则最大后验概率的权重为
(12) $\hat{w}_{c}=\left(\boldsymbol{K} \boldsymbol{K}^{\mathrm{T}}+\boldsymbol{A}_{c}\right)^{-1} \boldsymbol{K} \boldsymbol{y}_{c}^{\mathrm{T}}$
(13) $\begin{array}{c}p(\boldsymbol{A} \mid \boldsymbol{W}) \propto p(\boldsymbol{W} \mid \boldsymbol{A}) p(\boldsymbol{A} \mid a, b) \propto p \prod_{c=1}^{c} \prod_{n=1}^{N} G\left(a+\frac{1}{2}, \frac{w_{m}^{2}+2 b}{2}\right)\end{array}$
3.3 果蝇算法优化的多分类相关向量机
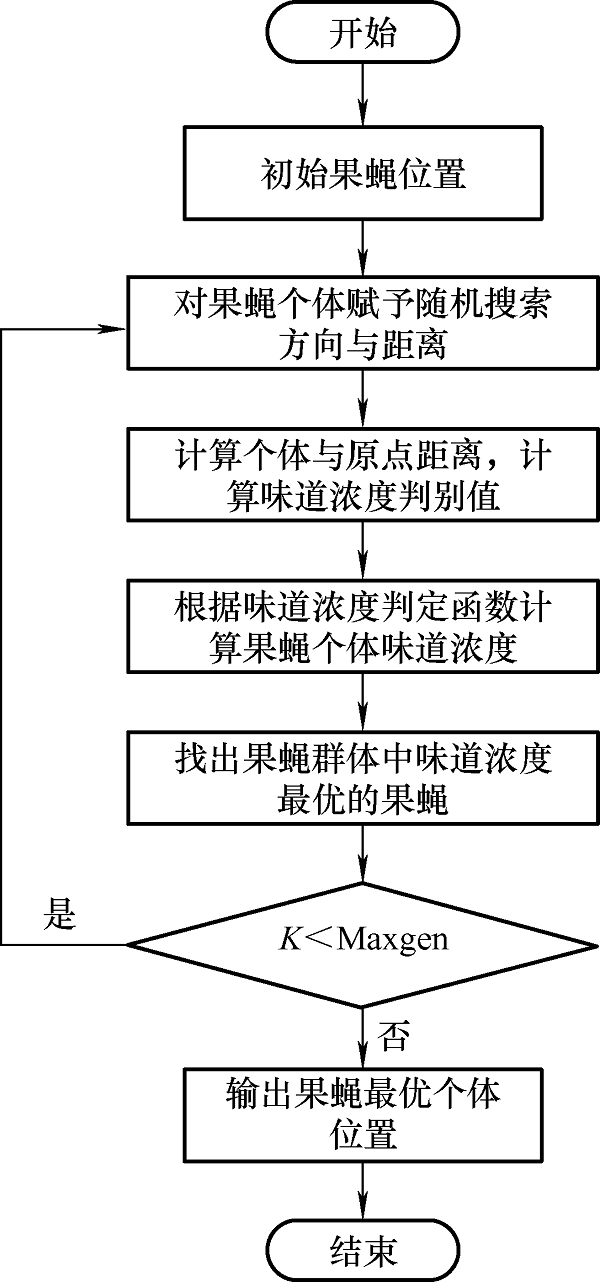
果蝇算法被广泛用于机器学习的参数优化,大大提高了机器学习的效率[16 ] 。其中,种群大小取10,复杂的取20~50;搜索半径为一正整数,搜索方向为0~1之间的随机数;迭代次数要根据计算结果,一般迭代次数越多,结果越精准,但太多会导致效率低下。
(3) 计算每个果蝇到原点长度和味道浓度的判定数值。
(4) 将浓度判定值代入适应函数中,计算果蝇位置和味道浓度值。
(6) 把步骤(5)的最优值记录下来,所有果蝇朝这个方向飞去。
图2
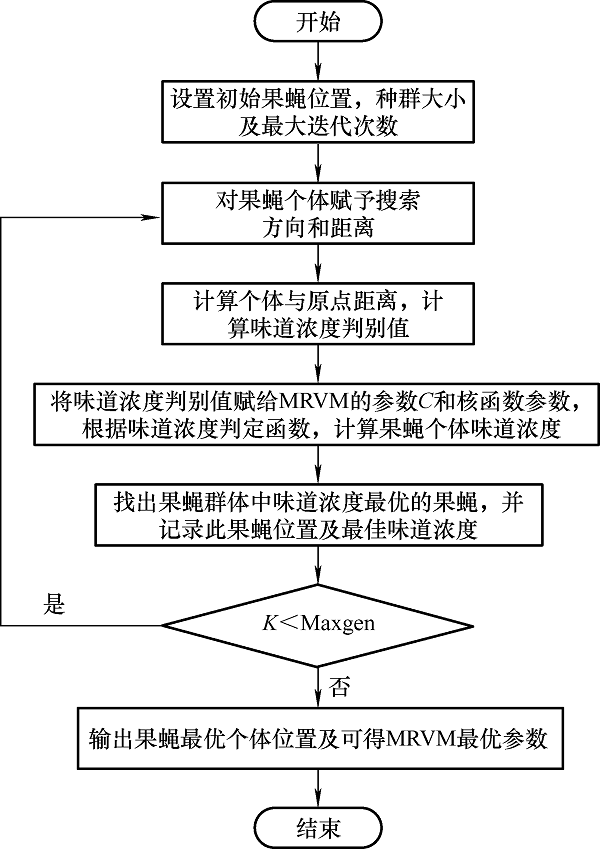
MRVM核函数参数的选择对模型具有较大影响,包括惩罚参数、径向基核函数参数和敏感因子。仅人为经验选择参数不能达到理想效果,达不到精度要求,因此,本文选择果蝇算法进行寻优,流程图如图3 所示。
图3
3.4 台区线损计算
由于变压器台区线损的指标量纲不同,因此需要对其进行归一化处理,选取台区线损率作为MRVM的输出,其输出值域为(0,1),因此需要将线损率归一化在(0,1)区间内。本文采用式(14)进行归一化处理[17 ]
(14) $d_{i}^{\prime}=\frac{d_{i}-d_{\min }}{d_{\max }-d_{\min }}$
式中,di 为归一化前的值;di 为归一化后的值;dmax 和dmin 分别为样本最大值及最小值。
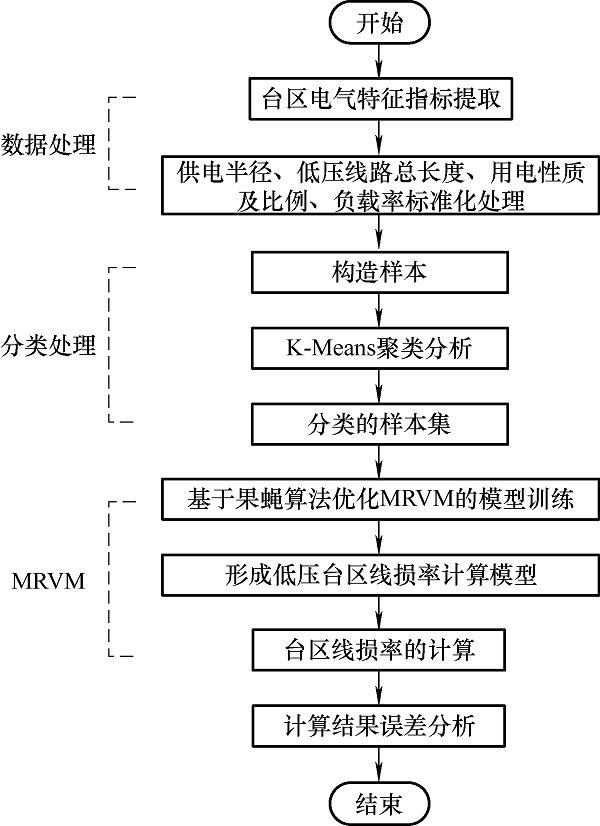
3.4.2 结合K-Means和MRVM的线损计算步骤分析
结合K-Means聚类算法和果蝇算法优化MRVM模型计算低压台区线损率分为4个步骤,具体如下。
(1) 选取台区线损的电气特征参数指标,并对其标准化处理。
(2) 利用K-Means聚类算法将台区样本进行聚类处理。
(3) 利用果蝇算法优化的MRVM模型计算台区线损率。
本文采用均方误差Em 来衡量计算结果的整体误差,假设台区样本数为N ,计算公式如下[18 ]
(15) $E_{m}=\left[\sum_{i=1}^{N-1}\left(d_{i}-o_{i}\right)^{2}\right] /(N-1)$
除整体误差外,还需要考虑单个样本误差情况即相对误差,计算方法如下[19 ] 所示
(16) $E_{C}=\left(O_{i}-d_{i}\right) / d_{i} \times 100 \%$
图4
4 实例分析
4.1 低压台区样本分类
为了验证该模型计算的实用性,一共选取了600个样本,按照第2节所述,选取台区4个指标作为输入,分别为:x 1 为居民用电比例,x 2 为供电半径,x 3 为低压线路长度,以及x 4 为负载率,输出为线损率d(%)。
使用上述600样本进行聚类分析,然后根据标准化后的数据计算样本的性能指标P E ,然后根据性能指标的大小进行排序[20 ] 。通过聚类分析发现,当聚类数目k 等于6时,聚类结果的轮廓系数达到最大值,因此本文把k 值设为6。根据P E 值把样本分为6类,则样本的聚类中心如表1 所示。
由表2 可知,6个类别所含样本数分别为150、301、11、40、85和13,总共600个样本。
4.2 低压台去线损率计算及误差分析
使用上述6类样本分别训练果蝇算法优化多分类相关向量机(MRVM)模型,在训练时,设置目标误差分别为:0.01、0.005、0.001、0.000 1,得到线损率结果如表3 所示。
由表3 可知,训练目标误差越小,模型计算结果越准确,但迭代次数增多,同时有可能出现不收敛的情况。果蝇算法优化MRVM模型在训练目标误差为0.000 1时仍然能够实现全局收敛,线损率E C 结果非常小,迭代次数达到480次,时间消耗为6 s,时间消耗仍在可接受范围内。
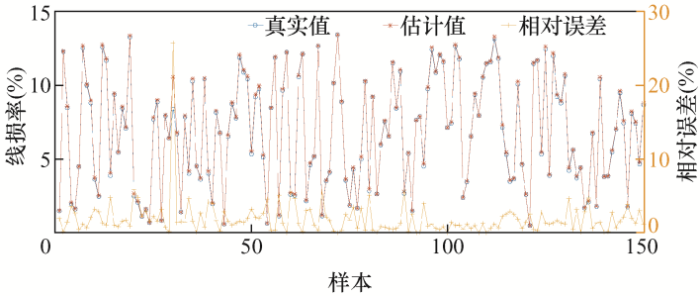
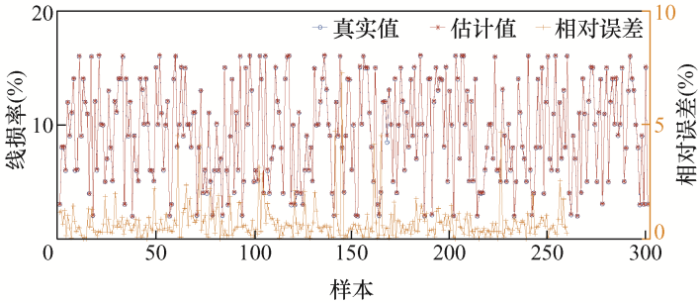
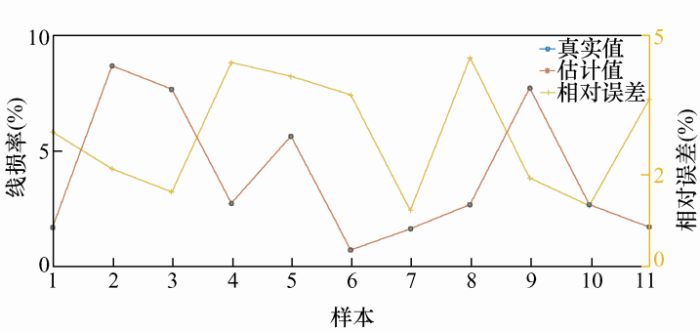
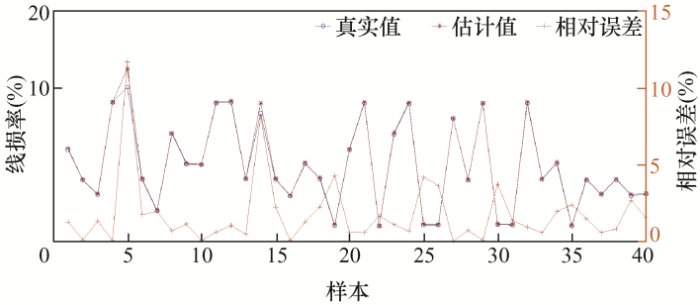
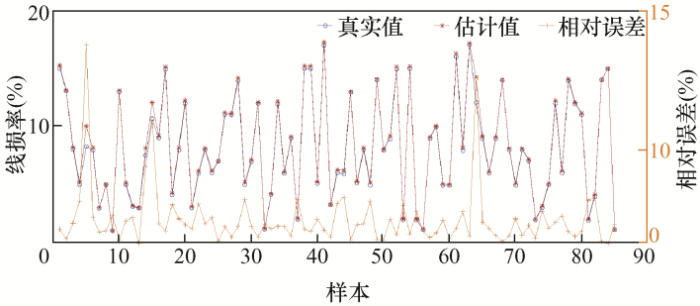
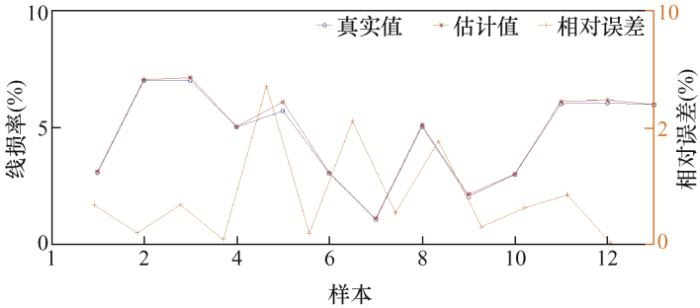
设置训练目标误差为0.000 1,得到实际线损率和估计线损率,6类样本计算结果如图5 ~10所示。
图5
图6
图7
图8
图9
图10
以上为6类样本的误差结果分析,从图5 中可看出第1类样本中的样本30的误差率达到了25.7%;第2类样本的误差率都在10%以下,误差率最高的样本168,误差率也才7.3%;第3类样本误差率在0.5%以内,误差非常小;第4类样本误差率最大的为样本5,达到了11.7%,样本14误差率为8.2%,其他样本误差率都小于5%;第5类样本的样本5误差率达到了21.4%,样本15和样本64误差率分别为13.2%和17.6%,其余样本误差率均在10%以下;第6类样本中,样本5误差率最高为6.8%,样本7次之,误差率为5.3%。下面对误差率在10%以上的样本校核。
根据电力系统相关理论,特征指标值越大,则线损率越大,然而对比第五类样本的5号、15号和64号,5号样本的X 1 、X 2 、X 3 、X 4 均小于15号和64号对应的指标值,然而其实测线损率最大,因此可判断5号实测值不准确,需要重新校核;同理可对比第五类样本的15号和64号,15号样本线损率理应小于64号样本线损率,然而实测线损值得到相反结果,因此可推测15号和64号的实测值存在问题。依此对比一类样本的30号和四类样本的5号,需要重新校核实际测量的线损值,然后和模型的预测值作对比。通过校核后,得到这5个台区样本的线损率为11.31%、11.22%、10.14%、12.17%、14.28%,重新计算相对误差率,得知误差率都下降到了5%以下。
4.3 果蝇算法优化MRVM模型和标准MRVM结果比较
为了验证基于果蝇算法优化MRVM模型的优越性,设置目标误差为0.01,把计算结果进行比较,结果如表5 所示。
通过表5 可看出,果蝇算法优化的MRVM跌得次数更少,且有更高的线损计算准确率。
5 结论
本文提出了一种新的低压台区线损率计算方法,把该计算方法应用于资阳低压台区线损计算,得到如下结果。
(1) 通过K-Means聚类算法对台区样本进行聚类分析,可解决以为台区样本分散导致的计算误差较大的问题。
(2) 在台区分类后,搭建果蝇算法优化的M-RVM线损率计算模型,并对其进行训练,得到线损率计算结果
(3) 对资阳地区的600个台区样本进行实例验证,通过计算证明了该算法具有较快的收敛速度和准确率。
参考文献
View Option
[1]
章元德 , 史亮 , 陆巍 , 等 . 线损信息化统计中数据质量管控机制及实现
[J]. 电力系统自动化 , 2016 ,40 (7 ):128 -133 .
[本文引用: 1]
ZHANG Yuande SHI Liang LU Wei , et al . Realization of data management and control mechanism of line loss statistical inofrmation
[J]. Automation of Electric Power System , 2016 ,40 (7 ):128 -133 .
[本文引用: 1]
[2]
高卫东 , 宋斌 . 月度实际线损率定量计算方法
[J]. 电力系统自动化 , 2012 ,36 (2 ):86 -90 .
[本文引用: 1]
GAO Weidong SONG Bin . A quantitative calculation method for actual monthly line loss rate
[J]. Automation of Electric Power System , 2012 ,36 (2 ):86 -90 .
[本文引用: 1]
[3]
罗洁青 . 广州荔湾区配电网线损分析及降损措施研究
[D]. 广州:华南理工大学 , 2012 .
[本文引用: 1]
LUO Jieqing . Studies on line loses of distribution networks and measures for reducing line loss in Liwan district of Guangzhou
[D]. Guangzhou:South China University of Technology , 2012 .
[本文引用: 1]
[4]
颜伟 , 吕志盛 , 李佐君 , 等 . 输电网的蒙特卡罗模拟与线损概率评估
[J]. 中国电机工程学报 , 2007 (34 ):41 -47 .
[本文引用: 1]
YAN Wei LÜ Zhisheng LI Zuojun , et al . Monte Carlo simulation and transmission loss evalution with probabilistic method
[J]. Proceedings of the CSEE , 2007 (34 ):41 -47 .
[本文引用: 1]
[5]
王守相 , 周凯 , 苏运 . 基于随机森林算法的台区合理线损率估计方法
[J]. 电力自动化设备 , 2017 ,37 (11 ):39 -45 .
[本文引用: 1]
WANG Shouxiang ZHOU Kai SU Yun . Line loss rate estimation method of transformer districtbased on random forest algorithm
[J]. Automation of Electric Power Systems , 2017 ,37 (11 ):39 -45 .
[本文引用: 1]
[6]
邹云峰 , 梅飞 , 李悦 , 等 . 基于数据挖掘技术的台区合理线损预测模型研究
[J]. 电力需求侧管理 , 2015 (4 ):25 -29 .
[本文引用: 1]
ZOU Yunfeng MEI Fei LI Yue , et al . Prediction model research of reasonable line loss for transformer district based on data mining technology
[J]. Power Demand Side Management , 2015 (4 ):25 -29 .
[本文引用: 1]
[7]
姜惠兰 , 安敏 , 刘晓津 , 等 . 基于动态聚类算法径向基函数网络的配电网线损计算
[J]. 中国电机工程学报 , 2005 (10 ):35 -39 .
URL
[本文引用: 1]
提出了基于径向基函数网络的计算配电网线损的实用方法.对有代表性的配电线路的线损与特征参数的样本数据,采用一种新的动态聚类算法进行聚类,来确定RBF网络的隐含层节点,不仅聚类速度快,而且隐含层节点数的优化提高了网络的利用效率.利用RBF网络强的拟合特性映射线损与特征参数之间复杂的非线性关系,使网络学习了配电线路在结构参数和运行参数变化时线损的趋势规律.以68条配电线路数据为例,仿真结果验证了文中提出的方法具有网络模型简单、学习速度快、线损计算精度高等优点.
JIANG Huilan AN Min LIU Xiaojin , et al . The calculation of energy losses in distribution systems based on RBF network with dynamic clustering algorithm
[J]. Proceedings of the CSEE , 2005 (10 ):35 -39 .
[本文引用: 1]
[8]
李滨 , 严康 , 罗发 , 等 . 最优标杆在市级电网企业线损精益管理中的综合应用
[J]. 电力系统自动化 , 2018 ,42 (23 ):184 -192 .
[本文引用: 1]
LI Bin YAN Kang LUO Fa , et al . Comprehensive application of optimal benchmarking in line loss lean management of city-level power grid enteprises
[J]. Automation of Electric Power Systems , 2018 ,42 (23 ):184 -192 .
[本文引用: 1]
[9]
王潇笛 , 刘俊勇 , 刘友波 . 采用自适应分段聚合近似的典型负荷曲线形态聚类算法
[J]. 电力系统自动化 , 2019 ,43 (1 ):150 -161 .
[本文引用: 1]
WANG Xiaodi LIU Junyong LIU Youbo . Shape clustering algorithm of typical load curves based on adaptive piecewise aggregate approximation
[J]. Automation of Electric Power Systems , 2019 ,43 (1 ):150 -161 .
[本文引用: 1]
[10]
张绍德 , 毛雪菲 , 毛雪芹 . 基于最近邻聚类支持向量机辨识的电弧炉电极逆控制
[J]. 控制理论与应用 , 2010 (7 ):85 -91 .
[本文引用: 1]
ZHANG Shaode MAO Xuefei MAO Xueqin . Inverse control for electrodes in electric arc furnace based onsupport-vector-machines identification on nearest neighbor clustering
[J]. Control Theory & Applications , 2010 (7 ):85 -91 .
[本文引用: 1]
[11]
王保义 , 胡恒 , 张少敏 . 差分隐私保护下面向海量用户的用电数据聚类分析
[J]. 电力系统自动化 , 2018 ,42 (2 ):121 -127 .
[本文引用: 1]
WANG Baoyi HU Heng ZHANG Shaomin . Clustering analysis of power consumption data to mass users under differential privacy protection
[J]. Automation of Electric Power Systems , 2018 ,42 (2 ):121 -127 .
[本文引用: 1]
[12]
CHITSAZ H AMJADY N ZAREIPOUR H . Wind power forecast using wavelet neural network trained by improved Clonal selection algorithm
[J]. Energy Conversion & Management , 2015 ,89 :588 -598 .
[本文引用: 1]
[13]
律方成 , 金虎 , 王子建 , 等 . 基于主成分分析和多分类相关向量机的GIS局部放电模式识别
[J]. 电工技术学报 , 2015 ,30 (6 ):225 -231 .
[本文引用: 1]
LÜ Fangcheng JIN Hu WANG Zijian , et al . GIS partial discharge pattern recognition based on principal component analysis and milticlass relevance vector machine
[J]. Transactions of China Electrotechnical Society , 2015 ,30 (6 ):225 -231 .
[本文引用: 1]
[14]
尹金良 . 基于相关向量机的油浸式电力变压器故障诊断方法研究
[D]. 北京:华北电力大学 , 2013 .
[本文引用: 1]
YIN Jinliang . Fault diagnosis method of oil immersed power transformer based on relevance vector machine
[D]. Beijing:North China Electric Power University , 2013 .
[本文引用: 1]
[15]
吴小文 , 李擎 . 果蝇算法和5种群智能算法的寻优性能研究
[J]. 火力与指挥控制 , 2013 (4 ):21 -24,29 .
[本文引用: 1]
WU Xiaowen LI Qing . Research of optimizing performance of fruit fly optimizationalgorithm and five kinds of intelligent algorithm
[J]. Fire Control&Command Control , 2013 (4 ):21 -24,29 .
[本文引用: 1]
[16]
胡能发 . 演化式果蝇算法及其应用研究
[J]. 计算机技术与发展 , 2013 ,23 (7 ):131 -133,137 .
[本文引用: 1]
HU Nengfa . Evolutionary fruit algorithm and its application research
[J]. Computer Technology and Development , 2013 ,23 (7 ):131 -133,137 .
[本文引用: 1]
[17]
周建英 , 宋奕冰 , 刘宪林 , 等 . 网络最大流法在配电网线损计算中的应用
[J]. 电力系统及其自动化学报 , 2000 (5 ):13 -16 .
[本文引用: 1]
ZHOU Jianying SONG Yibing LIU Xianlin , et al . Application of network maximal flow in the computation of distribution network losses
[J]. Proceedings of the EPSA , 2000 (5 ):13 -16 .
[本文引用: 1]
[18]
RAUTIO J C DEMIR V . Microstrip conductor loss models for electromagnetic analysis
[J]. IEEE Trans. Mtt. , 2003 ,51 (3 ):915 -921 .
[本文引用: 1]
[19]
姜惠兰 , 安敏 , 刘晓津 , 等 . 基于动态聚类算法径向基函数网络的配电网线损计算
[J]. 中国电机工程学报 , 2005 (10 ):37 -41 .
[本文引用: 1]
JIANG Huilan AN Min LIU Xiaojin , et al . The calculation of energy losses in distribution systems based on RBF network with dynamic clustering algorithm
[J]. Proceedings of the CSEE , 2005 (10 ):37 -41 .
[本文引用: 1]
[20]
徐茹枝 , 王宇飞 . 粒子群优化的支持向量回归机计算配电网理论线损方法
[J]. 电力自动化设备 , 2012 ,32 (5 ):86 -89 .
[本文引用: 1]
XU Ruzhi WANG Yufei . Theoretical line loss calculation based on SVR and PSO for distribution system
[J]. Electic Power Automation Equipment , 2012 ,32 (5 ):86 -89 .
[本文引用: 1]
线损信息化统计中数据质量管控机制及实现
1
2016
... 低压配电系统的线损管理是电力系统线损管理的重要组成部分,涉及配电系统的规划、运行、营销和计量.统计的线损包含管理线损,但由于低压配电系统网络结构复杂、用户数量多、性质复杂、海量数据管理困难等原因,低压配电系统线损计算存在较大偏差[1 ] .理论线损的计算是基于电网设备参数、操作数据和功率流以及载荷分布理论,它可以准确地了解电网损耗的构成,并且提供一个可靠的依据充分利用电网企业的潜在 损失. ...
线损信息化统计中数据质量管控机制及实现
1
2016
... 低压配电系统的线损管理是电力系统线损管理的重要组成部分,涉及配电系统的规划、运行、营销和计量.统计的线损包含管理线损,但由于低压配电系统网络结构复杂、用户数量多、性质复杂、海量数据管理困难等原因,低压配电系统线损计算存在较大偏差[1 ] .理论线损的计算是基于电网设备参数、操作数据和功率流以及载荷分布理论,它可以准确地了解电网损耗的构成,并且提供一个可靠的依据充分利用电网企业的潜在 损失. ...
月度实际线损率定量计算方法
1
2012
... 配电网处于发电、输电、配电的末端,其设备数量多、覆盖范围广、电压等级低,导致配电网损耗大.到目前为止,低压配电系统的线损仅根据用户文件进行简单计算,未考虑负荷、供电半径的影响.此外,目前的计算周期一般都是按日计算,当运行方式发生变化时,无法进行实时线损计算[2 ] .随着分布式可再生能源的广泛集成,低压配电系统中的潮流、线损、电压分布发生了变化,对低压配电系统的线损管理产生了很大的影响. ...
月度实际线损率定量计算方法
1
2012
... 配电网处于发电、输电、配电的末端,其设备数量多、覆盖范围广、电压等级低,导致配电网损耗大.到目前为止,低压配电系统的线损仅根据用户文件进行简单计算,未考虑负荷、供电半径的影响.此外,目前的计算周期一般都是按日计算,当运行方式发生变化时,无法进行实时线损计算[2 ] .随着分布式可再生能源的广泛集成,低压配电系统中的潮流、线损、电压分布发生了变化,对低压配电系统的线损管理产生了很大的影响. ...
广州荔湾区配电网线损分析及降损措施研究
1
2012
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
广州荔湾区配电网线损分析及降损措施研究
1
2012
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
输电网的蒙特卡罗模拟与线损概率评估
1
2007
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
输电网的蒙特卡罗模拟与线损概率评估
1
2007
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于随机森林算法的台区合理线损率估计方法
1
2017
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于随机森林算法的台区合理线损率估计方法
1
2017
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于数据挖掘技术的台区合理线损预测模型研究
1
2015
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于数据挖掘技术的台区合理线损预测模型研究
1
2015
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于动态聚类算法径向基函数网络的配电网线损计算
1
2005
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
基于动态聚类算法径向基函数网络的配电网线损计算
1
2005
... 配电网理论线损计算方法主要有前向-后向扫描法、等效电阻法(容量法和电学法)、均方根电流法、平均电流法、最大电流法等[3 ] .这些算法以前受配电网自动化程度的限制,在使用时存在不同的局限性,如计算工作量大,没有考虑负荷曲线变化的差异、各负荷节点的实际功率、节点电压、线路电抗等[4 ] .近年来,人工智能算法的发展逐渐应用于线损率计算,比如利用神经网络搭建计算模型,通过大量的样本训练,拟合特征参数和线损之间的关系.文献[5 ]引入多源数据,并通过随机森林法搭建线损计算模型,在一定程度上提高了线损计算效率;文献[6 ]通过建立线性回归模型进行数据挖掘来预测线损率,得到较好的准确率;文献[7 ]通过聚类算法来确定神经网络的隐层节点,来构建线损计算模型,具有较快的计算速度. ...
最优标杆在市级电网企业线损精益管理中的综合应用
1
2018
... 为了改善多分类相关向量机的性能,需要优化输入参数,减少维度.通过现场经验和相关电力系统理论知识得知影响台区线损率的参数有供电半径、线路长度、负载率、用电性质、三项不平衡度、电压等,考虑参数的影响大小及获取难易程度,选取与低压台区线损率密切相关的4个电气参数作为输入.通过反复筛选,选取了供电半径、线路总长、负载率以及用电种类及用电种类占比情况[8 ] ,由于研究的是低压台区线损,因此选用居民用电性质来表示用电性质. ...
最优标杆在市级电网企业线损精益管理中的综合应用
1
2018
... 为了改善多分类相关向量机的性能,需要优化输入参数,减少维度.通过现场经验和相关电力系统理论知识得知影响台区线损率的参数有供电半径、线路长度、负载率、用电性质、三项不平衡度、电压等,考虑参数的影响大小及获取难易程度,选取与低压台区线损率密切相关的4个电气参数作为输入.通过反复筛选,选取了供电半径、线路总长、负载率以及用电种类及用电种类占比情况[8 ] ,由于研究的是低压台区线损,因此选用居民用电性质来表示用电性质. ...
采用自适应分段聚合近似的典型负荷曲线形态聚类算法
1
2019
... 为了减少网架结构带来的计算误差,需要对台区样本进行聚类分析.在对其进行聚类前,首先要计算样本之间的相似度,一般用距离来表示相似度.本文采用K-Means聚类算法来对台区进行聚类分析,该算法以距离作为相似性的评价指标,以误差平方和准则函数作为聚类准则函数,是一种迭代求解的聚类分析算法,该算法步骤如下[9 ] 所示. ...
采用自适应分段聚合近似的典型负荷曲线形态聚类算法
1
2019
... 为了减少网架结构带来的计算误差,需要对台区样本进行聚类分析.在对其进行聚类前,首先要计算样本之间的相似度,一般用距离来表示相似度.本文采用K-Means聚类算法来对台区进行聚类分析,该算法以距离作为相似性的评价指标,以误差平方和准则函数作为聚类准则函数,是一种迭代求解的聚类分析算法,该算法步骤如下[9 ] 所示. ...
基于最近邻聚类支持向量机辨识的电弧炉电极逆控制
1
2010
... 为了解决以上问题,本文通过聚类结果的轮廓系数St 确定K 的大小,轮廓系数的计算方法如式(6)所示[10 ] ...
基于最近邻聚类支持向量机辨识的电弧炉电极逆控制
1
2010
... 为了解决以上问题,本文通过聚类结果的轮廓系数St 确定K 的大小,轮廓系数的计算方法如式(6)所示[10 ] ...
差分隐私保护下面向海量用户的用电数据聚类分析
1
2018
... 为了解决局部收敛问题,可以多次随机选取聚类中心,最后比较各自完成后的畸变函数值,畸变函数越小,则说明聚类效果更优[11 ] . ...
差分隐私保护下面向海量用户的用电数据聚类分析
1
2018
... 为了解决局部收敛问题,可以多次随机选取聚类中心,最后比较各自完成后的畸变函数值,畸变函数越小,则说明聚类效果更优[11 ] . ...
Wind power forecast using wavelet neural network trained by improved Clonal selection algorithm
1
2015
... 本文选取低压台区供电半径,低压线路总长,负载率以及用电比例最小值作为电气指标值,台区评价指标如式(8)所示[12 ] ...
基于主成分分析和多分类相关向量机的GIS局部放电模式识别
1
2015
... 多分类相关向量机(MRVM)是在相关向量机(RVM)的基础上进行了扩展,该算法相关向量数量少,泛化能力强,可解决小样本、非线性问题.MRVM使用分层贝叶斯模型,能以概率形式给出结果,便于分析问题的不确定性[13 ] . ...
基于主成分分析和多分类相关向量机的GIS局部放电模式识别
1
2015
... 多分类相关向量机(MRVM)是在相关向量机(RVM)的基础上进行了扩展,该算法相关向量数量少,泛化能力强,可解决小样本、非线性问题.MRVM使用分层贝叶斯模型,能以概率形式给出结果,便于分析问题的不确定性[13 ] . ...
基于相关向量机的油浸式电力变压器故障诊断方法研究
1
2013
... 式中,ync 表示矩阵Y 的n 行c 列;wc 表示矩阵W的第c 列;Nx (m,v)表示变量x 服从正态分布.设多项概率联系函数$t_{n}=i, y_{n}>y_{n j} \forall j \neq i$,则多项概率似然函数公式为[14 ] ...
基于相关向量机的油浸式电力变压器故障诊断方法研究
1
2013
... 式中,ync 表示矩阵Y 的n 行c 列;wc 表示矩阵W的第c 列;Nx (m,v)表示变量x 服从正态分布.设多项概率联系函数$t_{n}=i, y_{n}>y_{n j} \forall j \neq i$,则多项概率似然函数公式为[14 ] ...
果蝇算法和5种群智能算法的寻优性能研究
1
2013
... 式中,u 服从均值为0,方差为1的正态分布,为了提高模型的稀疏性,使$\alpha_{n c}$服从超参数分别为a ,b 的Gamma分布[15 ] .MRVM采用分层贝叶斯模型结构,由上述可知其模型结构如图1 所示. ...
果蝇算法和5种群智能算法的寻优性能研究
1
2013
... 式中,u 服从均值为0,方差为1的正态分布,为了提高模型的稀疏性,使$\alpha_{n c}$服从超参数分别为a ,b 的Gamma分布[15 ] .MRVM采用分层贝叶斯模型结构,由上述可知其模型结构如图1 所示. ...
演化式果蝇算法及其应用研究
1
2013
... 果蝇算法被广泛用于机器学习的参数优化,大大提高了机器学习的效率[16 ] .其中,种群大小取10,复杂的取20~50;搜索半径为一正整数,搜索方向为0~1之间的随机数;迭代次数要根据计算结果,一般迭代次数越多,结果越精准,但太多会导致效率低下. ...
演化式果蝇算法及其应用研究
1
2013
... 果蝇算法被广泛用于机器学习的参数优化,大大提高了机器学习的效率[16 ] .其中,种群大小取10,复杂的取20~50;搜索半径为一正整数,搜索方向为0~1之间的随机数;迭代次数要根据计算结果,一般迭代次数越多,结果越精准,但太多会导致效率低下. ...
网络最大流法在配电网线损计算中的应用
1
2000
... 由于变压器台区线损的指标量纲不同,因此需要对其进行归一化处理,选取台区线损率作为MRVM的输出,其输出值域为(0,1),因此需要将线损率归一化在(0,1)区间内.本文采用式(14)进行归一化处理[17 ] ...
网络最大流法在配电网线损计算中的应用
1
2000
... 由于变压器台区线损的指标量纲不同,因此需要对其进行归一化处理,选取台区线损率作为MRVM的输出,其输出值域为(0,1),因此需要将线损率归一化在(0,1)区间内.本文采用式(14)进行归一化处理[17 ] ...
Microstrip conductor loss models for electromagnetic analysis
1
2003
... 本文采用均方误差Em 来衡量计算结果的整体误差,假设台区样本数为N ,计算公式如下[18 ] ...
基于动态聚类算法径向基函数网络的配电网线损计算
1
2005
... 除整体误差外,还需要考虑单个样本误差情况即相对误差,计算方法如下[19 ] 所示 ...
基于动态聚类算法径向基函数网络的配电网线损计算
1
2005
... 除整体误差外,还需要考虑单个样本误差情况即相对误差,计算方法如下[19 ] 所示 ...
粒子群优化的支持向量回归机计算配电网理论线损方法
1
2012
... 使用上述600样本进行聚类分析,然后根据标准化后的数据计算样本的性能指标P E ,然后根据性能指标的大小进行排序[20 ] .通过聚类分析发现,当聚类数目k 等于6时,聚类结果的轮廓系数达到最大值,因此本文把k 值设为6.根据P E 值把样本分为6类,则样本的聚类中心如表1 所示. ...
粒子群优化的支持向量回归机计算配电网理论线损方法
1
2012
... 使用上述600样本进行聚类分析,然后根据标准化后的数据计算样本的性能指标P E ,然后根据性能指标的大小进行排序[20 ] .通过聚类分析发现,当聚类数目k 等于6时,聚类结果的轮廓系数达到最大值,因此本文把k 值设为6.根据P E 值把样本分为6类,则样本的聚类中心如表1 所示. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}